
In this article, you will learn everything about how to read CSV files using PySpark with the help of the proper example. Most of the time as a developer or as a Data Engineer, your requirement is to load CSV data in Python to perform some transformations on that data,
There are various ways to load CSV data in Python but two popular ways from them are using Pandas and PySpark.
Throughout this article, you will see how to load single, multiple, and even all CSV files from a directory and also you will see how you can perform some transformations on the data contained by the CSV file, and finally will see how to write a new CSV file by newly transformed data.
PySpark provides few methods to read single or multiple CSV files. It accepts multiple parameters which we will discuss one by one with the help of the example.
Headings of Contents
- 1 What is PySpark?
- 2 What is CSV ( Comma Separated Values )?
- 3 What is DataFrame in PySpark?
- 4 Guide to Read CSV file into DataFrame using PySpark
- 5 How to read multiple CSV files using PySpark
- 6 Read All CSV files in a Directory
- 7 PySpark DataFrame Transformation with Example
- 8 Options While Reading CSV files
- 9 Read CSV File in PySpark With User Defined Schema
- 10 Write PySpark DataFrame to CSV File
- 11 Conclusion
What is PySpark?
PySpark is nothing but an API written in Python programming in order to work with Apache spark. It is an open-source, distributed cluster computing big data processing framework that comes with various components like SQL, Streaming, Mlib, Spark Core, etc.
If you are familiar with the Python Pandas library then you can easily start with PySpark also. Is used for large-scale data analysis and to create robust data pipelines.
What is CSV ( Comma Separated Values )?
CSV ( Comma Separated Values ) is a simple text-based file format that contains data separated by a delimiter. In the CSV file delimiter is called a symbol that separates all CSV file values, It may be commas ( Most popular ), pipe ( | ), etc. Each line of the CSV file is called a data record. A CSV file always saves with .csv extensions.
For example, You can see the below data which is the best example of CSV data.
Sample CSV Data:
name,department,birthday_month John Smith,Accounting,November Erica Meyers,IT,March Harshita,Sales,December Vishvajit,IT,July
As you can see in the above sample CSV data which comprises three things header, delimiter, and records.
- The first row represents the header of the CSV file.
- The rest of the data except the header are called records.
- All the commas are called delimiters which separate values.
What is DataFrame in PySpark?
DataFrame in PySpark is a core data structure just like a list, tuple, or dictionary in Python. It is used to store data in tabular format just like tables in Relation to Database Management Systems ( RDBMS ). It is an immutable data structure in PySpark meaning of immutable means is that it can not be changed once it has been created.
Always a new DataFrame will be returned when any operation will be applied on top of PySpark DataFrame.
A DataFrame will be returned when we will load CSV file data using PySpark.
I have shown you a simple PySpark data frame.
+--------+-----------------+----------+------+
|name |designation |department|salary|
+--------+-----------------+----------+------+
|Rambo |Developer |IT |33000 |
|John |Developer |IT |40000 |
|Harshita|HR Executive |HR |25000 |
|Vanshika|Senior HR Manager|HR |50000 |
|Harry |SEO Analyst |Marketing |33000 |
|Shital |HR Executive |HR |25000 |
+--------+-----------------+----------+------+Guide to Read CSV file into DataFrame using PySpark
There are two ways to read CSV files using PySpark, csv(“file path”) and format(“csv”).load(“file path”) methods. The csv(“file path”) is the PySpark DataFrameReader method which takes the path of the CSV file and returns the result as a DataFrame and it also accepts various parameters also.
The format(“csv”) and load(“file path”) are also DataFrameReader methods which are capable of reading CSV files along with various parameters.
We will see both ways to read CSV files. But you have to remember one thing here, when you are using the format() method then you have to specify the file name which you are going to read, for example, format(“json”), format(“csv”), format(“text”), etc.
CSV Data
For this article, I have attached a CSV file format screenshot below where I have separated the header section, records section, and delimiter so that you can understand more about a CSV file.
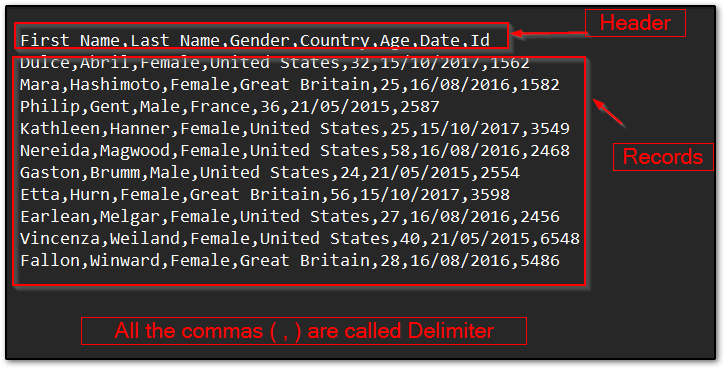
In the above screenshot:
- The first row items ( First Name, Last Name, Gender, Country, Age, Date, Id ) are called header.
- All Commas (,) are called delimiters, I might be different in your case.
- The rest of the data except the header are called records.
Read CSV files using the csv() method
The csv() is a method written inside DataFrameReader class. It accepts the path of the file along with various parameters to read CSV files. It is also capable of reading multiple CSV files together. But here, I am about to load only a CSV file.
Let’s see how to read a CSV file using the csv() method.
Example: Reading CSV file using csv() method:
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# reading csv file called sample_data.csv
dataframe = spark.read.csv("sample_data.csv")
# display dataframe
dataframe.printSchema()
Read CSV file using format() and load() method
These two both format() and load() methods are also used to read CSV files. These two are methods written inside the PySpark DataFrameReader class. The format() method takes file short names like json, csv, text, parquet, etc, and the load() method takes the path of the file you want to read along with parameters.
let’s see how can you these two methods.
Example: Read CSV file using format and load() method:
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# reading csv file
dataframe = spark.read.format("csv").load("sample_data.csv")
# print schema
dataframe.printSchema()
When you will run any one of these two examples, you will get an output like this.
root
|-- _c0: string (nullable = true)
|-- _c1: string (nullable = true)
|-- _c2: string (nullable = true)
|-- _c3: string (nullable = true)
|-- _c4: string (nullable = true)
|-- _c5: string (nullable = true)
|-- _c6: string (nullable = true)Note:- printSchema() is used to display the schema of the DataFrame. Schema means column name and data type.
In the above output, _c0 represents the name of the first column, _c1 represents the name of the second column, _c2 represents the name of the third column and so on and string represents the name of the datatype of the column.
Display PySpark DataFrame
Dataframe has the show() method which is used to display the data frame. You can simply call the show() method using the data frame instance in order to display the PySpark DataFrame.
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# reading csv file
dataframe = spark.read.format("csv").load("sample_data.csv")
# display dataframe
dataframe.show()
Output
+----------+---------+------+-------------+---+----------+----+
| _c0| _c1| _c2| _c3|_c4| _c5| _c6|
+----------+---------+------+-------------+---+----------+----+
|First Name|Last Name|Gender| Country|Age| Date| Id|
| Dulce| Abril|Female|United States| 32|15/10/2017|1562|
| Mara|Hashimoto|Female|Great Britain| 25|16/08/2016|1582|
| Philip| Gent| Male| France| 36|21/05/2015|2587|
| Kathleen| Hanner|Female|United States| 25|15/10/2017|3549|
| Nereida| Magwood|Female|United States| 58|16/08/2016|2468|
| Gaston| Brumm| Male|United States| 24|21/05/2015|2554|
| Etta| Hurn|Female|Great Britain| 56|15/10/2017|3598|
| Earlean| Melgar|Female|United States| 27|16/08/2016|2456|
| Vincenza| Weiland|Female|United States| 40|21/05/2015|6548|
| Fallon| Winward|Female|Great Britain| 28|16/08/2016|5486|
+----------+---------+------+-------------+---+----------+----+In the above DataFrame, one thing is wrong which is the header, As you can see the first row, Columns ( First Name, Last Name, Gender, Country, Age, Date, Id ) should be the header whereas it became part of the data records.
let’s make the first row a header in PySpark DataFrame.
Using Header Record For Column Names
If your CSV file contains a row for the header, then you can explicitly specify True for the header using the option() method. If you specify the option(“header”, “true”) then it will treat the first records of the CSV file as a header otherwise it will treat it as a record.
dataframe = spark.read.option("header", "true").format("csv").load("sample_data.csv")
dataframe.show()
Now, the first row of the CSV file successfully becomes a part of the column name and your DataFrame will be like this.
+----------+---------+------+-------------+---+----------+----+
|First Name|Last Name|Gender| Country|Age| Date| Id|
+----------+---------+------+-------------+---+----------+----+
| Dulce| Abril|Female|United States| 32|15/10/2017|1562|
| Mara|Hashimoto|Female|Great Britain| 25|16/08/2016|1582|
| Philip| Gent| Male| France| 36|21/05/2015|2587|
| Kathleen| Hanner|Female|United States| 25|15/10/2017|3549|
| Nereida| Magwood|Female|United States| 58|16/08/2016|2468|
| Gaston| Brumm| Male|United States| 24|21/05/2015|2554|
| Etta| Hurn|Female|Great Britain| 56|15/10/2017|3598|
| Earlean| Melgar|Female|United States| 27|16/08/2016|2456|
| Vincenza| Weiland|Female|United States| 40|21/05/2015|6548|
| Fallon| Winward|Female|Great Britain| 28|16/08/2016|5486|
+----------+---------+------+-------------+---+----------+----+Display a specific number of rows in DataFrame
You can pass a number inside the show() method to display a specific number of records in the DataFrame.Here, I am about to display only 4 records in The data frame by passing the 4 inside the show() method.
dataframe.show(4)
+----------+---------+------+-------------+---+----------+----+ |First Name|Last Name|Gender| Country|Age| Date| Id| +----------+---------+------+-------------+---+----------+----+ | Dulce| Abril|Female|United States| 32|15/10/2017|1562| | Mara|Hashimoto|Female|Great Britain| 25|16/08/2016|1582| | Philip| Gent| Male| France| 36|21/05/2015|2587| | Kathleen| Hanner|Female|United States| 25|15/10/2017|3549| +----------+---------+------+-------------+---+----------+----+
How to read multiple CSV files using PySpark
The csv() method is also capable of reading multiple CSV files. It accepts a string or list of CSV files path and loads all the CSV files.
path = ["sample_data.csv", "students.csv"] dataframe = spark.read.csv(path, header=True)
Read All CSV files in a Directory
In order to read all the CSV files from a folder or directory, you have to just pass the path of the directory in the csv() method. It will automatically detect all the CSV files and load them into the data frame.
dataframe = spark.read.csv("csv_files", header=True)
In the above example, csv_files represents the name of the folder which contained all the CSV files.
PySpark DataFrame Transformation with Example
DataFrame Transformation means, The process of doing some modification in the existing PySpark data frame according to business need and generating a new data frame.
There are various data frame methods are available to perform a transformation on top of the data frame but throughout this article, we will see only some methods.
Suppose our requirement is to add a new Column in DataFrame called full_name. The full_name column should be contained a concatenation of the first_name and last_name.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, concat_ws
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# reading csv file
dataframe = spark.read.csv("sample_data.csv", header=True)
print("DataFrame - Before Transformation")
dataframe.show()
print("DataFrame - After Transformation")
df = dataframe.withColumn("Full Name", concat_ws(' ', col("First Name"), col("Last Name")))
df.show()
In the above example, the col() function takes the column name as a parameter, and the concat_ws() function takes the separator and values to be added.
For the above example, col(“First Name”) and col(“Last Name”) represent the value of First Name and Last Name and the first parameter of concat_ws() is called separator which separates the values that are passed to concat_ws() function to be concatenated.
As you can see in the below result set, How I have concatenated two columns First Name and Last Name, and made a new column Full Name.
DataFrame - Before Transformation
+----------+---------+------+-------------+---+----------+----+
|First Name|Last Name|Gender| Country|Age| Date| Id|
+----------+---------+------+-------------+---+----------+----+
| Dulce| Abril|Female|United States| 32|15/10/2017|1562|
| Mara|Hashimoto|Female|Great Britain| 25|16/08/2016|1582|
| Philip| Gent| Male| France| 36|21/05/2015|2587|
| Kathleen| Hanner|Female|United States| 25|15/10/2017|1876|
+----------+---------+------+-------------+---+----------+----+
DataFrame - After Transformation
+----------+---------+------+-------------+---+----------+----+---------------+
|First Name|Last Name|Gender| Country|Age| Date| Id| Full Name|
+----------+---------+------+-------------+---+----------+----+---------------+
| Dulce| Abril|Female|United States| 32|15/10/2017|1562| Dulce Abril|
| Mara|Hashimoto|Female|Great Britain| 25|16/08/2016|1582| Mara Hashimoto|
| Philip| Gent| Male| France| 36|21/05/2015|2587| Philip Gent|
| Kathleen| Hanner|Female|United States| 25|15/10/2017|1876|Kathleen Hanner|
+----------+---------+------+-------------+---+----------+----+---------------+Options While Reading CSV files
PySpark provides various options along with different meanings in order to read CSV files. I have explained some popular options which can be used with CSV API during the reading of CSV files.
header
This option is used to read the first line of the CSV file as a header. If your CSV file contains the first line as a header Then you need to explicitly specify option(“header”, “true”) or options(header=True) or header=True inside csv() method. If you do not specify header is True then CSV API will treat the first line of the CSV file as data records. The default value of the header is False.
df = spark.read.option('header', 'true').csv("path of csv file")
or
df = spark.read.options(header=True).csv("path of csv file")
or
df = spark.read.csv("path of csv file", header=True)
inferSchema
When you read a CSV file without inferSchema then CSV API read the data type of every column as a string. If you specify inferSchema is True then it will infer the schema or Data type of column according to the column value. The default value of inferSchema is set to False.
df = spark.read.option('inferSchema', 'true').csv("path of csv file")
or
df = spark.read.options(inferSchema=True).csv("path of csv file")
or
df = spark.read.csv("path of csv file", inferSchema=True)
delimiter
The delimiter represents the symbol that separates the values in the CSV file by default it is set to a comma (,). it can be anything any like pipe | ), tab ( \t ), space( ), etc.
As you can see below sample CSV data where the comma (,) represents the delimiter.
students.csv
name,department,birthday_month John Smith,Accounting,November Erica Meyers,IT,March Harshita,Sales,December Vishvajit,IT,July
df = spark.read.option('delimiter', ',').csv("students.csv")
Read CSV files with Quotes
The quote option in csv() method is used to set the single character to escape the quoted value where the separator can be a part of the values.
students.csv:
name,department,birthday month John Smith,Accounting,November Erica Meyers,IT,March Harshita,Sales,December Vishvajit,Rao,IT,July
In the above CSV data, (Vishvajit, Rao) is a part of the name column but when you will try to read the CSV file Then CSV API separates both Vishvajit and Rao because it accepts delimiter as a comma (,) by default.
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# reading csv file
df = spark.read.option("header", "true").csv("students.csv")
df.show()
Output
+------------+----------+--------------+
| name|department|birthday month|
+------------+----------+--------------+
| John Smith|Accounting| November|
|Erica Meyers| IT| March|
| Harshita| Sales| December|
| Vishvajit| Rao| IT|
+------------+----------+--------------+As you can see in the above DataFrame, Rao became the part of department column but it shouldn’t be. To fix this problem you have to specify Vishvajit, Rao in single double quotes and use quote options in csv() method. quote option used double quotes by default.
After quoting Vishvajit and Rao, CSV data will be like this.
students.csv
name,department,birthday month John Smith,Accounting,November Erica Meyers,IT,March Harshita,Sales,December 'Vishvajit,Rao',IT,July
Code to read the above CSV data along with the quote option.
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# reading csv file
df = spark.read.option("header", "true").csv("students.csv", quote="'")
df.show()
After executing the above code, the new DataFrame will be like this.
+-------------+----------+--------------+
| name|department|birthday month|
+-------------+----------+--------------+
| John Smith|Accounting| November|
| Erica Meyers| IT| March|
| Harshita| Sales| December|
|Vishvajit,Rao| IT| July|
+-------------+----------+--------------+Read CSV File in PySpark With User Defined Schema
User-defined schema is used when you don’t want to use inferSchema. It allows you to write your own schema to read or write and CSV file. This is also called data type in PySpark because it has the functionality to define the data type of column while reading CSV files.
To read the CSV file in PySpark with the schema, you have to import StructType() from pyspark.sql.types module. The StructType() in PySpark is the data type that represents the row. The StructType() has a method called add() which is used to add a field or column name along with the data type.
Let’s see the full process of how to read CSV files on PySpark with schema.
We have a sample CSV file that contains the following data. To read this data we will create a user-defined schema using StructType().
sample_data.csv
First Name,Last Name,Gender,Country,Age,Date,Id Dulce,Abril,Female,United States,32,2017-10-15,1562 Mara,Hashimoto,Female,Great Britain,25,2016-08-16,1582 Philip,Gent,Male,France,36,2015-05-21,2587 Kathleen,Hanner,Female,United States,25,2017-10-15,1876
Code to read CSV file with schema:
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, DateType
# creating user define schema
schema = (
StructType()
.add("First Name", StringType(), True)
.add(
"Last Name",
StringType(),
True,
).add("Gender", StringType(), True)
.add("Country", StringType(), True)
.add("Age", IntegerType(), True)
.add("Date", DateType(), True)
.add("Id", IntegerType(), True)
)
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# reading csv file
dataframe = spark.read.schema(schema=schema).csv("sample_data.csv", header=True)
# displaying DataFrame
dataframe.show()
# displaying schema
dataframe.printSchema()
Output
+----------+---------+------+-------------+---+----------+----+
|First Name|Last Name|Gender| Country|Age| Date| Id|
+----------+---------+------+-------------+---+----------+----+
| Dulce| Abril|Female|United States| 32|2017-10-15|1562|
| Mara|Hashimoto|Female|Great Britain| 25|2016-08-16|1582|
| Philip| Gent| Male| France| 36|2015-05-21|2587|
| Kathleen| Hanner|Female|United States| 25|2017-10-15|1876|
+----------+---------+------+-------------+---+----------+----+
root
|-- First Name: string (nullable = true)
|-- Last Name: string (nullable = true)
|-- Gender: string (nullable = true)
|-- Country: string (nullable = true)
|-- Age: integer (nullable = true)
|-- Date: date (nullable = true)
|-- Id: integer (nullable = true)Write PySpark DataFrame to CSV File
Sometimes, your requirement can be saved loaded, or transformed data to a new CSV file.PySpark has the option to save the data frames to a new CSV file. To save PySpark DataFrame to a CSV file, PySpark provides a DataFrame write property.
The DataFrame write property returns the object of the PySpark DataFrameWriter class.
For example, We have a sample CSV file that contains some data and I want to add a new column called Full Name with the addition of First Name and Last Name columns after that I will create a new CSV file named new_csv_file.csv
let’s see how can We do that.
sample_data.csv:
First Name,Last Name,Gender Dulce,Abril,Female Mara,Hashimoto,Female Philip,Gent,Male Kathleen,Hanner,Female
Code to write PySpark DataFrame to CSV file:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, concat_ws
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# reading csv file
df = spark.read.csv("sample_data.csv", header=True, inferSchema=True)
# transformation
new_df = df.withColumn("Full Name", concat_ws(" ", col("First Name"), col("Last Name")))
# write DataFrame to new CSV file
new_df.write.options(header=True).csv("new_csv_data")
After executing the above code a new CSV file new_csv_data.csv will be created.
First Name,Last Name,Gender,Full Name Dulce,Abril,Female,United States,Dulce Abril Mara,Hashimoto,Female,Great Britain,Mara Hashimoto Philip,Gent,Male,Philip Gent Kathleen,Hanner,Female,Kathleen Hanner
Options White Write CSV File
There are various options while writing a CSV file, It is almost the same as when we were reading the CSV files. You can use any option according to your requirements.
Let’s understand some options by using examples.
header:
The header option is almost the same as the header option while reading the CSV files. During writing a CSV file you can use the header option True. The header option basically adds the first line of the CSV file as a header which represents the column in CSV.
# write DataFrame to new CSV file
new_df.write.options(header=True).csv("new_csv_data")
delimiter:
The delimiter is used to separate the values in CSV files. You can use any symbol as a delimiter. By default, it uses commas (,).
# write DataFrame to new CSV file
new_df.write.options(header=True, delimiter=",").csv("new_csv_data")
Saving Mode:
There are various saving modes available which you can use during the writing DataFrame to CSV file. To use the saving mode, you have to use the mode() method which is a DataFrameWriter method. It takes a saving mode as a parameter.
Saving modes are:
- overwrite:- This saving mode is used to overwrite the content of the existing files.
df.write.options(header=True, delimiter=",").mode("overwrite").csv("my_new_csv")
- append:- This saving mode is used to append or add the content to an existing file.
df.write.options(header=True, delimiter=",").mode("append").csv("my_new_csv")
- ignore:- It ignores the write operations when files exist.
df.write.options(header=True, delimiter=",").mode("ignore").csv("my_new_csv")
- error:- This is the default option of the mode which returns an error when the file already exists.
References:
Conclusion
So, In this article, we have successfully covered all about how to read CSV files using PySpark with the help of the proper examples. I think you don’t have any confusion regarding, reading CSV files in Pyspark because we have covered approx all the basic concepts here.
You have to remember the following points when you are going to read CSV files.
- Import SparkSession from pyspark.sql module.
- Create a spark session using SparkSession.builder.appName(“testing”).getOrCreate().
- Use the read property to return DataFrameReader.
- Use csv() method which is a method of DataFrameReader and pass the path of the CSV file you want to read.
- Use the show() method to display the loaded CSV file data.
- And so another thing like Transformation, writing CSV file, etc
If you will all the above steps carefully, Then you can easily read CSV files using PySpark.
I hope you understand this article, If this article is helpful for you, please share and keep visiting for further PySpark tutorials.
Thanks for your valuable time…
Have a nice day…





