
In this data engineering tutorial, we will see the internal working of reduce action in PySpark with the help of the proper example and explanation. As a Data Engineering and PySpark Developer, we must know the internal workings of the reduce action.
Let’s start.
Headings of Contents
What is PySpark RDD?
RDD in PySpark is a core data structure just like Python list, tuple, dictionary, etc. RDD stands for Resilient Distributed Datasets. RDD is slightly different from the Python core data structure, which means It has the responsibility to distribute the datasets among multiple partitions and process them parallelly.
These partitions could be physical servers or nodes and one more important thing about the RDD is that is immutable which means we cannot change it once it has been created.
I hope you have understood the PySpark RDD if still you have confusion regarding PySpark RDD then you can check out our PySpark RDD tutorial.
What are PySpark RDD Actions?
PySpark RDD action is the process of returning a single value or evaluated RDD to return a single value or computed value to the driver program.
RDD action does not return any RDD as Output it always returns a single value or computed value.
Let’s understand all about PySpark RDD reduce action with the help of the example.
Syntax of PySpark RDD reduce action
In PySpark, the ‘reduce‘ function takes single parameters:
- Function:- It is a required parameter in the reduce function that is responsible for how you aggregate the elements of the RDD elements. This function must take two arguments which will indicate the two items of the RDD and return a single value after applying any operations.
Here is the syntax of the reduce function.
rdd.reduce(f)Note:- reduce cannnot work with empty rdd.You will get ValueError, if you will try.
Let’s see the usage of the reduce action.
To use reduce action, Firslty we need a PySpark RDD so that we can perform reduce action in top of that RDD.
Let me create a PySpark RDD.
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.appName("ProgrammingFunda.com")
.master("local[*]")
.getOrCreate()
)
sc = spark.sparkContext
lst = [1, 2, 3, 4, 5, 6, 7]
rdd = sc.parallelize(lst, 3)
print(rdd.collect())
The Output will be: [1, 2, 3, 4, 5, 6, 7]
In the above example:
- First, I have imported the SparkSession to create the object of the SparkSession class.
- Second, I have created a spark context that will be responsible for creating RDD with the help of the spark.sparkContext.
- Defined a Python list with some items.
- Create a PySpark RDD with the help of the spark context parallelize() method and this method takes two parameters iterable and num of partitions. In my case number of partitions is 3 which means lst will be distributed among three partitions.
- After that, I printed the RDD using the collect action.
Now It’s time to implement reduce action.
Using reduce action with built-in function:
Here, I am about to add all the elements of the rdd. To add all the elements of RDD I am using the RDD function from the operator module of Python which is a built-in function written in the operator module of Python.
To use it, we need to import the add function from operator the module.
from pyspark.sql import SparkSession
from operator import add
spark = (
SparkSession.builder.appName("ProgrammingFunda.com")
.master("local[*]")
.getOrCreate()
)
sc = spark.sparkContext
lst = [1, 2, 3, 4, 5, 6, 7]
rdd = sc.parallelize(lst, numSlices=3)
print(rdd.reduce(add))
The output would be 28.
In the above example, the add function takes two arguments that will be the two items of the RDD and aggregates them into a single value and this process will happen until all the items within each partition of the RDD are aggregated in a single result.
Using reduce action with lambda function:
We can also use the lambda function in PySpark reduce action, Let’s see how we can use the lambda function in PySpark reduce function to perform addition.
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.appName("ProgrammingFunda.com")
.master("local[*]")
.getOrCreate()
)
sc = spark.sparkContext
lst = [1, 2, 3, 4, 5, 6, 7]
rdd = sc.parallelize(lst, numSlices=3)
print(rdd.reduce(lambda x, y: x + y))
The output would be 28.
As you can see, the Lambda function takes two arguments and returns the sum of those two arguments.
Using reduce action with user-defined function:
The reduce action also takes a user-defined function as input. Let’s create a Python function that will take two arguments and return the sum of both arguments.
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.appName("ProgrammingFunda.com")
.master("local[*]")
.getOrCreate()
)
sc = spark.sparkContext
def addition(x, y):
return sum([x, y])
lst = [1, 2, 3, 4, 5, 6, 7]
rdd = sc.parallelize(lst, numSlices=3)
print(rdd.reduce(addition))
After executing the above code the Output will be: 28
So far we have seen implementation of the reduce function on top of the PySpark RDD but our main motive here is to get knowledge of the internal workings of the reduce function.
Let’s see, how does reduce action works in PySpark.
Internal Working of Reduce Action in PySpark
Let’s pick any example from the above to understand how reduce action works in PySpark internally. Here, I am using the last example.
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.appName("ProgrammingFunda.com")
.master("local[*]")
.getOrCreate()
)
sc = spark.sparkContext
def addition(x, y):
return sum([x, y])
lst = [1, 2, 3, 4, 5, 6, 7]
rdd = sc.parallelize(lst, numSlices=3)
print(rdd.reduce(addition))
We all know the output will be 28 but how?
Now, Let’s break down the internal workings of the reduce action with partitions:
Partitioning:
- As you can see, We explicitly partitioned the RDD into 3 partitions using
numSlices=3. - Each partition now contains a subset of the data: [1, 2], [3 4] and [5, 6, 7].
Task Distribution:
- Spark distributes these partitions across the worker nodes in the cluster.
- Each worker node operates independently and processes one or more partitions assigned to it.
Task Execution:
- On each worker node, the aggregation function (addition) is applied to the elements within its assigned partitions.
- The function is applied recursively to combine pairs of elements until only a single result remains within each partition.
- Each worker node will execute the addition function to find the sum of elements within its assigned partition.
Partial Aggregation:
- As the aggregation function is applied within each partition, intermediate results are generated. These intermediate results represent the aggregated values within each partition.
- For partition [1, 2], the intermediate result is 3 (sum of elements).
- For partition [3, 4], the intermediate result is 7.
- For partition [5, 6, 7], the intermediate result is 18.
Shuffle and Exchange (if necessary):
Since the reduce action does not require a shuffle, no data movement across partitions is needed in this example.
Merge and Final Aggregation:
The final step involves merging the intermediate results from different partitions and applying the reduce function recursively to combine pairs of elements until only one result remains.
In our example, the final aggregation would involve summing the intermediate results (3, 7, and 18) to produce the overall result.
The final result, which is the sum of all elements (28), is sent back to the driver program.
Result Collection:
The driver program collects the final result and outputs it.
In summary, by explicitly partitioning the RDD, we control how the data is distributed across the worker nodes, which can affect the parallelism and efficiency of the reduce action.
For more reference, You can see the below picture.
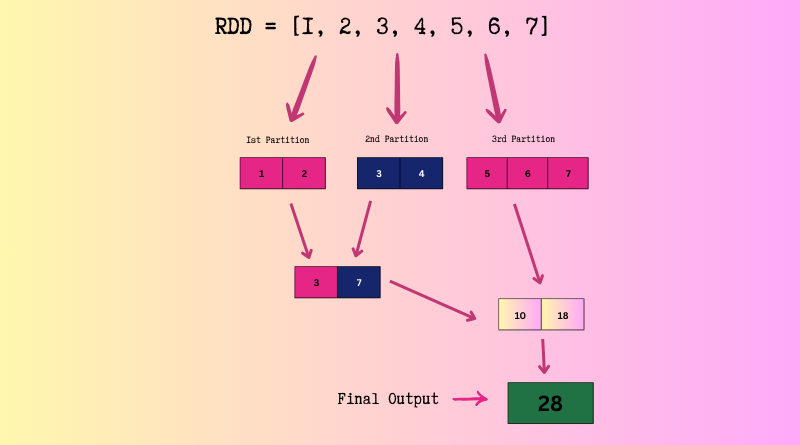
This is how reduce action works in PySpark internally.
Now, let’s wrap up this article.
Conclusion
So, In today’s article, we have seen the internal working of reduce action in PySpark with the the help of the example. As Data Engineers and PySpark developers, we must know that reducing action and its working because it makes you an efficient engineer.
If you found this article helpful, please share and keep visiting for further interesting PySpark tutorials.
Thanks for your valuable time….





