
Hi, In this tutorial, you will learn everything about the PySpark RDD ( Resilient Distributed Datasets ) with the help of the examples. By the end of this article, You must have come to know about PySpark RDD and its features, RDD transformations, and actions and processes to create RDD in PySpark.
PySpark is one of the most powerful tools to process huge amounts of data on multiple nodes of the cluster.PySpark provides two core Data structures to process the data RDD ( Resilient Distributed Datasets ) and DataFrame.
You can learn PySpark DataFrame from here. Today we will cover only the PySpark RDD ( Resilient Distributed Datasets ).
Headings of Contents
- 1 What is PySpark RDD ( Resilient Distributed Datasets )?
- 2 PySpark RDD Features
- 3 Creating PySpark RDD ( Resilient Distributed Datasets )
- 4 Creating RDD using the parallelize() method
- 5 Creating a PySpark RDD from a Txt File
- 6 Create an empty RDD using emptyRDD() Method:
- 7 Creating PySpark RDD using wholeTextFiles() Method:
- 8 PySpark RDD Operations
- 9 PySpark RDD Transformation
- 10 PySpark RDD Actions
- 11 Conclusion
What is PySpark RDD ( Resilient Distributed Datasets )?
PySpark RDD is a core data structure in PySpark just like Python list, tuple, set, etc but it is different from these data structures. RDD stands for Resilient Distributed Datasets. It is a collection of objects which process the data parallelly in multiple physical servers in a cluster. Physical servers are also called nodes.
Immutable means we can’t change RDD once the PySpark RDD has been created. Every time A new RRDD will be created whenever any transformation is applied to the existing RDD.
As we know, RDD is a collection of objects that’s why it divides the records into logical partitions which can be computed on multiple nodes or physical machines in a cluster.
This feature makes it different from Python core data structures like lists, tuples, sets, etc.
PySpark provides multiple transformations and action methods that can be applied on top of RDD ( Resilient Distributed Datasets ) to make changes to get the final output from RDD.
Some important points about PySpark RDD that you should remember:
- RDD is a fundamental data structure in PySpark that stores data on multiple nodes of a single or multi-cluster.
- PySpark RDD enables developers to process computation on large clusters.
- PySpark loads the data into memory or RAM ( Random Access Memory ) to process data that’s why it is more fast.
- PySpark does not evaluate the transformation until one of the actions is applied.
- PySpark RDD is a low-level API that provides more control over data.
PySpark RDD Features
These are the following key features of PySpark RDD ( Resilient Distributed Datasets ).
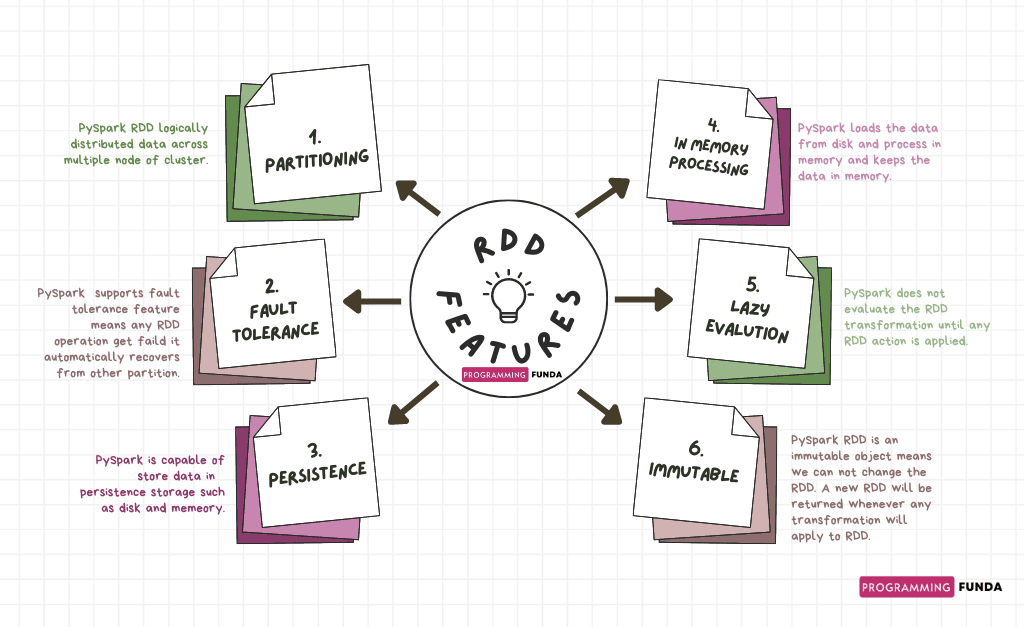
- Partitioning:
As we know, PySpark RDD is a collection of objects like Python lists, tuples, sets, etc. The only difference is that the Python list resided in a single location in the memory but PySpark RDD distributed each element on multiple physical machines or nodes of the cluster for parallel processing that’s why this process is called partitioning. - Fault Tolerance:
PySpark RDD is fault tolerance in nature which means, while working on any node, if any RDD operation fails it will automatically reload the data from the other partition. - Immutability:
PySpark RDD ( Resilient Distributed Datasets ) is an immutable object meaning when we apply any transformation on top of RDD then a new RDD will be returned always. Existing RDD will not be changed. In simple terms, PySpark RDD can’t be changed once it has been created. - Persistence
PySpark allows us to store all the data in persistent storage like storage or memory ( RAM ). Store data in memory is one of the most preferred ways because it increases the fast access of data. - In Memory Processing:
PySpark RDD can be used to store data. The data storage and size in PySpark RDD are independent. We can store any size of data in the RDD. Here, In-memory computation means, All the operations will be computed in main memory or RAM ( Random Access Memory ). - Lazy Evaluation:
PySpark RDD has multiple transformation methods. PySpark does not evaluate the transformations on the fly until any action method is applied. To execute all the applied transformations on top of the RDD, we will have to call the action method on that RDD. Until any action is applied to RDD, it keeps track of all the operations applied on RDD which is also called DAG ( Directed Acyclic Graph ).
So far we have seen the introduction of PySpark RDD and its Features of RDD,, now it is time to explore all about ways to create RDD in PySpark.
Creating PySpark RDD ( Resilient Distributed Datasets )
PySpark provides two ways to create RDD. We will see all of them one by one with the help of the example.
Before we jump into the example, we will have to create a spark session using the builder() method defined in the SparkSession class. During the creation of the spark session, we need to pass the master and application name as you can see below.
# creating spark session
spark = SparkSession.builder.master("local[3]").appName('www.programmingfunda.com').getOrCreate()
# creating spark context
sc = spark.sparkContext
Let me explain the above code:
- First, I have imported the SparkSession class from the pyspark.sql module.
- Second, I have created the spark session object where the builder is an attribute of the SparkSession class which is used to initialize the Builder() class. master() is a builder method that denotes where to run your spark application locally or cluster. It accepts URLs to connect. For example, if you are running a spark application locally, pass local[3] which means the application will run locally with 3 cores. You can pass any integer value instead of three but it must be greater than 0 which indicates the number of cores and the same number of partitions will be created. In my case, The three number of partitions will be created.
- Third, appName() is a method that is defined in the Builder class.it is used to set the name of the application. In my case application name is www.programmingfunda.com.
- Fourth, getOrCreate() returned a spark session object if not exist and created one if not exist.
- Fifth, Create a spark context using the sparkContext attribute of the Builder class.
Now Let’s see the process of creating RDD with the help of a spark context object.
We have multiple ways to create RDD ( Resilient Distributed Datasets ), Let’s see all of them one by one.
Creating RDD using the parallelize() method
The parallelize() is a kind of method written inside the SparkContext class. This method is used to create an RDD ( Resilient Distributed Datasets ). The parallelize() method takes an iterable as a parameter and returns an RDD.
The parallelize() method loads the data from the existing Python collections and distributes them across multiple partitions.
Here, I have defined a simple Python list along with some items and now I am going to convert that Python list to RDD, You can see below.
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.master("local[3]").appName('test').getOrCreate()
# creating spark context
sc = spark.sparkContext
# defining spark context
lst = ["Python", "PySpark", "Java", "Data Science", "Big Data", "Machine Learning", "Artificial Intelligence", "Deep Learning", "NLP", "Scrapping"]
# creating RDD
rdd = sc.parallelize(lst)
# displaying RDD
print("RDD:- ", rdd.collect())
Output
RDD:- ['Python', 'PySpark', 'Java', 'Data Science', 'Big Data', 'Machine Learning', 'Artificial Intelligence', 'Deep Learning', 'NLP', 'Scrapping']Looking at the above output, It would be difficult to identify how many partitions have been created, but in our case, the parallelize() method distributes the list into three separate partitions. The first partition has three items, the second partition has three items and the third partition has four items.
You can see the below diagram to understand RDD Partitions.
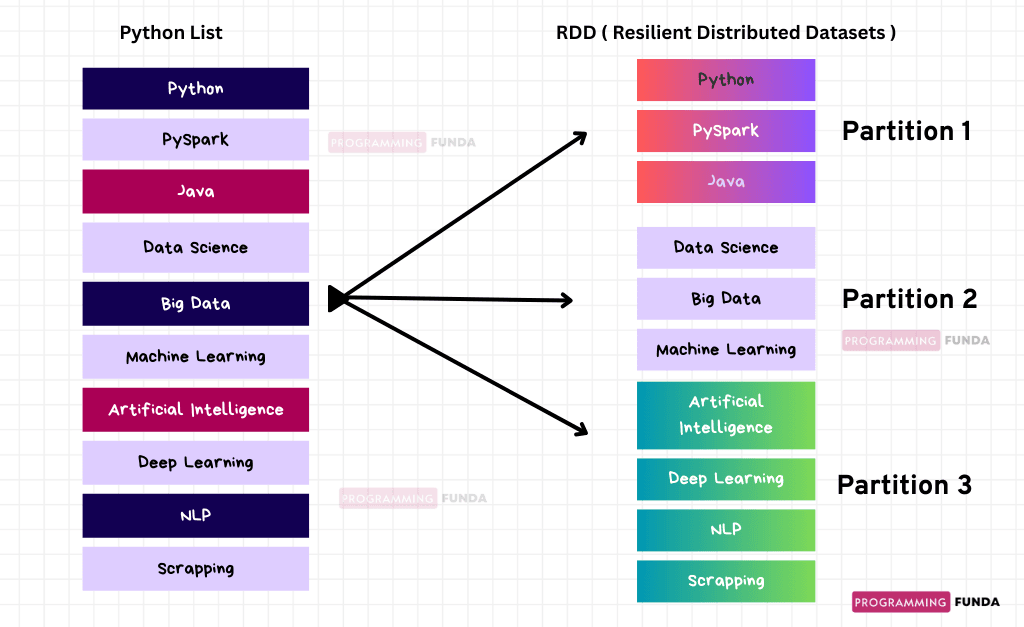
This is how you can use the parallelize() method to create RDD from a Python collection.
In The above picture, there are three partitions along with separate Dataset, this is why RDD is called collections of distributed datasets. I know that there are very small datasets but in real life, you will work with large datasets.
Creating a PySpark RDD from a Txt File
PySpark SparkContext provides a method called textFile() which is used to create an RDD from the text file. I have created a text file employee.txt along with some content as you can see below. The textFile() method reads each line as a single item of the RDD.
Let’s how can we use the textFile() method.
| employee.txt |
|---|
| name,designation,country Hayati,Developer,India Vishvajit,Developer,India Vaibhav,Tester,India Shital,HR,USA |
Code to Create RDD from a text file:
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.master("local[3]").appName('test').getOrCreate()
# creating spark context
sc = spark.sparkContext
rdd = sc.textFile('employee.txt')
print("The Output is:- ", rdd.collect())
Output
The Output is:- ['name,designation,country', 'Hayati,Developer,India', 'Vishvajit,Developer,India', 'Vaibhav,Tester,India', 'Shital,HR,USA']As you can see in the above output, each item indicates the line in the employee.txt file.
This is how we can use the textFile() method to create an RDD from the content of the text file.
Create an empty RDD using emptyRDD() Method:
SparkContext has another method to create an empty RDD ( Resilient Distributed Datasets ) with no partitions named emptyRDD().
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.master("local[3]").appName('test').getOrCreate()
# creating spark context
sc = spark.sparkContext
# creating empty rdd
rdd = sc.emptyRDD()
print("The Output is:- ", rdd.collect())
Output
The Output is:- []Creating PySpark RDD using wholeTextFiles() Method:
The wholeTextFiles() is also a SparkContext method that is used to create RDD along with partitions based on resource availability. The wholeTextFiles()returns paired RDD where the key indicates the file path and the value indicates the content of the file that you passed into the wholeTextFiles() method.
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.master("local[3]").appName('test').getOrCreate()
# creating spark context
sc = spark.sparkContext
rdd = sc.wholeTextFiles('employee.txt')
print("The Output is:- ", rdd.collect())
Output
The Output is:- [('file:/D:/Python Code/flask-app/pyspark_tutorials/employee.txt', 'name,designation,country\r\nHayati,Developer,India\r\nVishvajit,Developer,India\r\nVaibhav,Tester,India\r\nShital,HR,USA')]All the above SparkContex’s methods except emptyRDD() split the data into different-different partitions based on the resources available. When you are running into your laptop it will create several partitions as the same number of cores available in your laptop. However, we can pass the number of partitions to be created into the parallelize() method.
PySpark RDD Operations
There are two types of operations available in PySpark RDD ( Resilient Distributed Datasets ):
- Transformations
- Actions
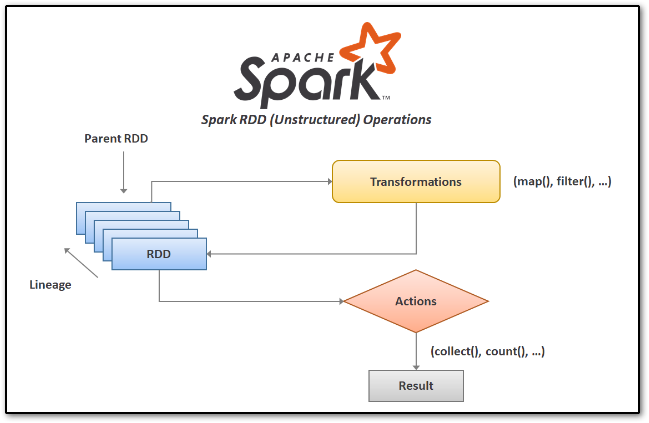
Transformations
As you can see in the above picture, Transformation is the process of making some changes in the RDD. Each time a new RDD will be returned when any transformation is applied to existing RDDs.RDD is lazy evaluation in nature means that transformations do not evaluate immediately until any action is applied on top of RDD.
PySpark keeps the status of all the parent RDDs of the RDD and creates a graph called the RDD Lineage Graph. Three are other names eixt of RDD Lineange Graph which are RDD Operator Graph and RDD Dependencies Graph.
Actions
As you can see in the above picture, RDD is a kind of operation that returns a single value or evaluates RDD to return a computed value. Action methods do not return RDD they compute the value after transformation and return the result to the driver program.
There are various action methods available in PySpark RDD.
PySpark RDD Transformation
As we know transformation is a kind of operation that is used to create a new RDD from an existing RDD after performing some Transformation. Again PySpark RDD Transformation is divided into two categories.
- Wider Transformation
- Narrow Transformation
Wide Transformation
Wider transformation is a kind of transformation in RDD that computes the data that lives in many partitions means there will be data movement from one partition to another partition.
In Wider Transformation. Data shuffling is required that’s why it is called shuffle transformation.
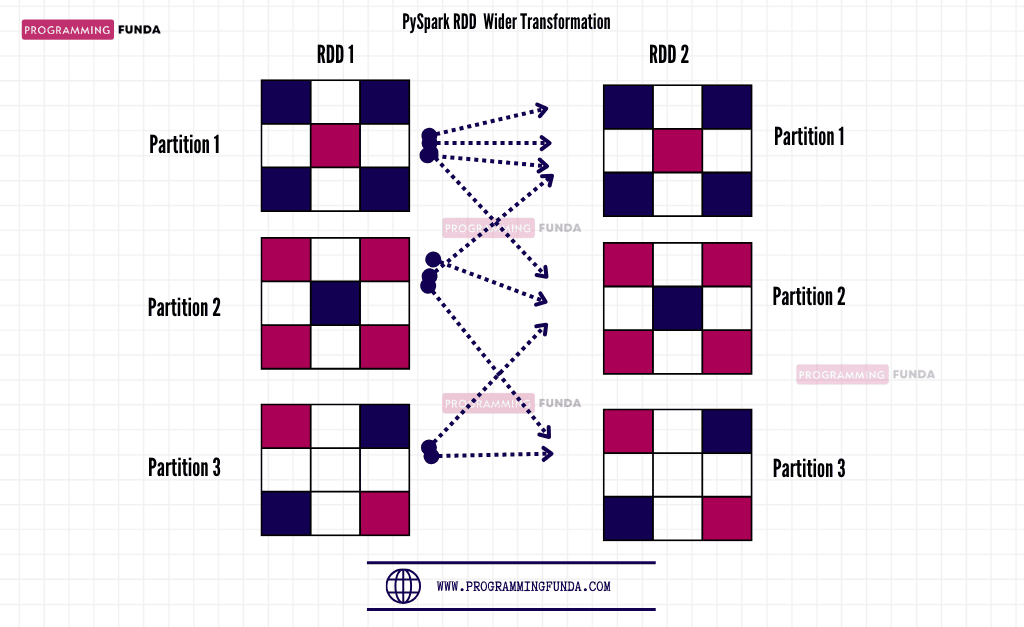
PySpark RDD Wider Transformation Methods:
| groupByKey() | sortByKey() | reduceByKey() |
| subtractByKey() | countByKey() | join() |
| intersection() | repartition() | distinct() |
| coalesce() | aggregateByKey() | combineByKey() |
PySpark RDD Narrow Transformation
Narrow transformation is a kind of transformation that does not require shuffling in the data means data will be computed that lives on a single partition. In Narrow transformation, there will not be movement of data between partitions.
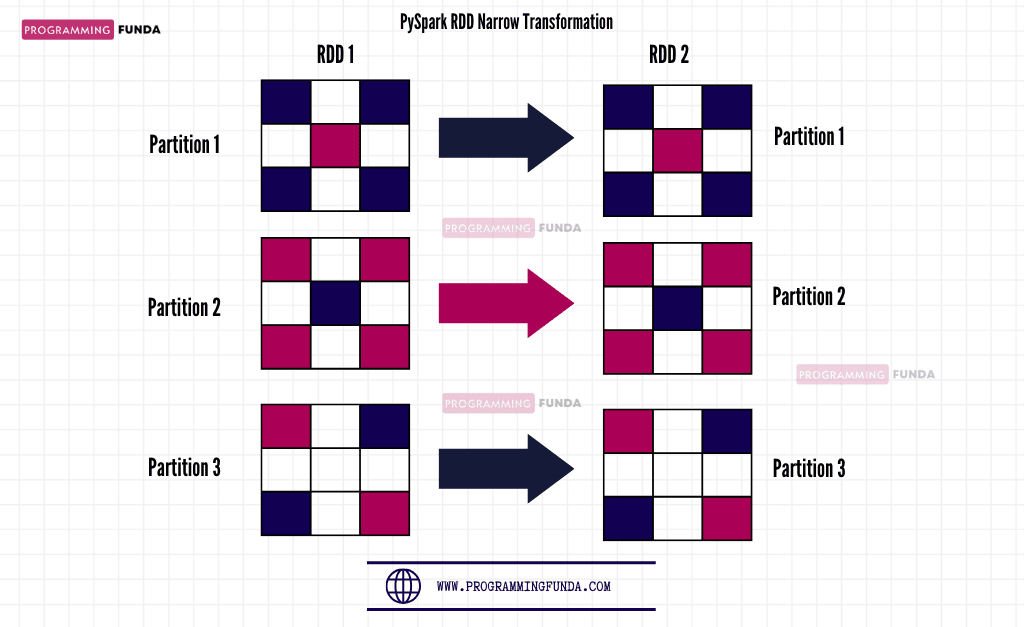
PySpark RDD Narrow Transformation Methods:
| map()count() | filter() | glom() | distinct() |
| union() | flatMap() | mapPartitionsWithIndex() | min() |
| mapPartitions() | sample() | mapPartitionsWithSplit() |
PySpark RDD Actions
As we know, PySpark Transformations are lazy they do not return the result to the driver program immediately. To return the result to the driver program, we have to use the action method on top of RDD.
In Other words, PySpark RDD Actions are the RDD operations that do not return RDD in the result.
Let’s Look at some common and mostly used action methods.:
| count() | first() | last() | collect() |
| countByValue() | top() | take() | min() |
| max() | mean() | sum() | reduce() |
| treeReduce() | fold() | collectAsMap() | countByValue() |
| foreach() | foreachPartition() | aggregate() | treeAggregate() |
| countApprox() | countApproxDistinct() | takeOrder() | takeSample() |
Note:- PySpark RDD Actions with Examples
Now, Let’s wrap up this tutorial here.
Conclusion
So, In this PySpark tutorial, we have seen all about PySpark RDD, RDD Features, RDD Operations, Type of RDD Operations, RDD Actions, and RDD Transformations. As a PySpark developer or Data engineer, we must know PySpark RDD because it is a fundamental data structure in PySpark and PySpark DataFrame is built on top of PySpark RDD.
If you found this article helpful, please share and keep visiting for further PySpark interesting tutorials.
Thanks for reading….





