
Hi PySpark Developers, In this article, we will see how to drop duplicate rows from PySpark DataFrame with the help of examples. PySpark DataFrame has some methods called dropDuplicates(), drop_duplicates(), and distinct(). We are about to see all these methods in order to get the only unique rows from the PySpark DataFrame.
Why do we need to remove duplicate rows from PySpark DataFrame?
While working with PySpark DataFrame, maybe, PySpark DataFrame contained duplicate rows. We should always remove duplicate rows from the PySpark DataFrame before applying any transformations and actions on top of that.
PySpark DataFrame provides some methods in order to drop duplicate rows from PySpark DataFrame. It all depends on your PySpark Project requirement. You can go with any methods of PySpark DataFrame but in this article, you will learn how to drop duplicate rows from PySpark DatFrame with the help of dropDuplicates(), drop_duplicates(), and distinct() methods.
Before removing duplicate rows, we must have a PySpark DataFrame. let’s create a PySpark DataFrame from CSV data. You can omit this part if you have already a PySpark DataFrame.
Headings of Contents
Creating PySpark DataFrame from CSV File
I have prepared a sample CSV file called sample_data.csv having some unique and duplicate records so that we can easily implement all the methods.
sample_data.csv:
First Name,Last Name,Gender,Country,Age,Date,Id Dulce,Abril,Female,United States,32,2017-10-15,1562 Mara,Hashimoto,Female,Great Britain,25,2016-08-16,1582 Philip,Gent,Male,France,36,2015-05-21,2587 Kathleen,Hanner,Female,United States,25,2017-10-15,1876 Mara,Hashimoto,Female,Great Britain,25,2016-08-16,1582 Kathleen,Hanner,Female,United States,25,2017-10-15,1876 Vishvajit,Rao,Male,India,24,2023-04-10,232 Ajay,Kumar,Male,India,27,2018-04-10,1234 Dulce,Abril,Female,United States,32,2017-10-15,1562 Vishvajit,Rao,Male,India,24,2023-04-10,232
PySpark Code to load CSV data into PySpark DataFrame:
Use below PySpark script to load the above CSV records into PySpark DataFrame.
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating PySpark DataFrame
dataframe = spark.read.option('header', 'true').csv('sample_data.csv')
# displaying
dataframe.show(truncate=False)
After the successful execution of the above code, The output will be:
+----------+---------+------+-------------+---+----------+----+
|first_name|last_name|gender|country |age|date |id |
+----------+---------+------+-------------+---+----------+----+
|Dulce |Abril |Female|United States|32 |2017-10-15|1562|
|Mara |Hashimoto|Female|Great Britain|25 |2016-08-16|1582|
|Philip |Gent |Male |France |36 |2015-05-21|2587|
|Kathleen |Hanner |Female|United States|25 |2017-10-15|1876|
|Mara |Hashimoto|Female|Great Britain|25 |2016-08-16|1582|
|Kathleen |Hanner |Female|United States|25 |2017-10-15|1876|
|Vishvajit |Rao |Male |India |24 |2023-04-10|232 |
|Ajay |Kumar |Male |India |27 |2018-04-10|1234|
|Dulce |Abril |Female|United States|32 |2017-10-15|1562|
|Vishvajit |Rao |Male |India |26 |2022-04-10|1232|
+----------+---------+------+-------------+---+----------+----+Explanation of the above PySpark Script:
- First, I imported SparkSession class from pyspark.sql module.
- Second, I have created a spark session called spark from SparkSession.builder.appName(“programmingfunda.com”).getOrCreate() where the builder has a Builder contracture to create Spark Session. The appName() is used to provide the name of the Pyspark application and the getOrCreate() method is used to return the existing spark session or create a new one If the spark session is not available.
- Third, Used spark.read.option(‘header’, ‘true’).csv(‘sample_data.csv’) in order to load CSV file data, where the read is an attribute of spark session that returns the object of DataFrameReader class, option() is the method of DataFrameReader class that is used to provide additional parameters for the CSV file and csv() method is used to load the CSV data, It takes the path of the CSV file.
- Finally displayed the loaded CSV data into PySpark DataFrame using the DataFrame show() method.
As you can see, The above DataFrame contained some duplicate rows, even that I have highlighted all those duplicate rows by some colors. As you can see below.
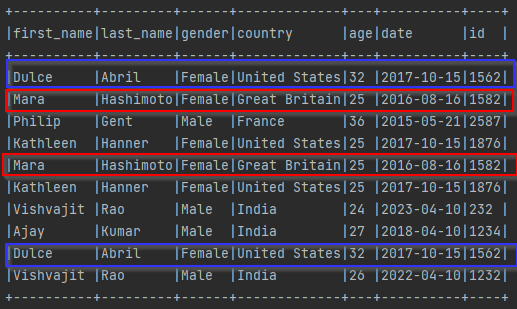
Now, let’s explore each of the methods like dropDuplicates(), drop_duplicates(), and distinct() to drop the duplicates rows from PySpark DataFrame.
PySpark DataFrame dropDuplicates() Method
It is a method that is used to return a new PySpark DataFrame after removing the duplicate rows from the PySpark DataFrame. It takes a parameter called a subset. The subset parameter represents the column name to check the duplicate of the data. It was introduced in Spark version 1.4.1.
Let’s implement the PySpark DataFrame dropDuplicates() method on top of PySpark DataFrame.
Example: Remove Duplicate Rows from PySpark DataFrame
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating PySpark DataFrame
dataframe = spark.read.option('header', 'true').csv('sample_data.csv')
# removing duplicate rows
dataframe = dataframe.dropDuplicates()
# displaying
dataframe.show(truncate=False)
After removing duplicate rows from DataFrame, The new DataFrame will be.
+----------+---------+------+-------------+---+----------+----+
|first_name|last_name|gender|country |age|date |id |
+----------+---------+------+-------------+---+----------+----+
|Philip |Gent |Male |France |36 |2015-05-21|2587|
|Vishvajit |Rao |Male |India |26 |2022-04-10|1232|
|Kathleen |Hanner |Female|United States|25 |2017-10-15|1876|
|Ajay |Kumar |Male |India |27 |2018-04-10|1234|
|Dulce |Abril |Female|United States|32 |2017-10-15|1562|
|Vishvajit |Rao |Male |India |24 |2023-04-10|232 |
|Mara |Hashimoto|Female|Great Britain|25 |2016-08-16|1582|
+----------+---------+------+-------------+---+----------+----+Example: Drop Duplicate Rows from PySpark DataFrame by Column
The dropDuplicates() methods take a parameter called subset which indicates the column name in order to check duplicacy of the records. For example, I am about to drop all those records whose first_name and last_name are the same.
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating PySpark DataFrame
dataframe = spark.read.option('header', 'true').csv('sample_data.csv')
# removing duplicate rows
dataframe = dataframe.dropDuplicates(subset=['first_name', 'last_name'])
# displaying
dataframe.show(truncate=False)
Output
+----------+---------+------+-------------+---+----------+----+
|first_name|last_name|gender|country |age|date |id |
+----------+---------+------+-------------+---+----------+----+
|Ajay |Kumar |Male |India |27 |2018-04-10|1234|
|Dulce |Abril |Female|United States|32 |2017-10-15|1562|
|Kathleen |Hanner |Female|United States|25 |2017-10-15|1876|
|Mara |Hashimoto|Female|Great Britain|25 |2016-08-16|1582|
|Philip |Gent |Male |France |36 |2015-05-21|2587|
|Vishvajit |Rao |Male |India |24 |2023-04-10|232 |
+----------+---------+------+-------------+---+----------+----+PySpark DataFrame drop_duplicates() Function
The drop_duplicates() function is also a PySpark DataFrame function that is used to remove the duplicate rows from the PySpark DatFrame method. The drop_duplicates() function is an alias of the dropDuplicates() method which means you can use the drop_duplicates() method in place of dropDuplicates() with the same parameters.
Example: Drop Duplicate Rows from PySpark DataFrame by Column
# removing duplicate rows dataframe = dataframe.drop_duplicates(['first_name', 'last_name']) dataframe.show()
Output
+----------+---------+------+-------------+---+----------+----+
|first_name|last_name|gender|country |age|date |id |
+----------+---------+------+-------------+---+----------+----+
|Ajay |Kumar |Male |India |27 |2018-04-10|1234|
|Dulce |Abril |Female|United States|32 |2017-10-15|1562|
|Kathleen |Hanner |Female|United States|25 |2017-10-15|1876|
|Mara |Hashimoto|Female|Great Britain|25 |2016-08-16|1582|
|Philip |Gent |Male |France |36 |2015-05-21|2587|
|Vishvajit |Rao |Male |India |24 |2023-04-10|232 |
+----------+---------+------+-------------+---+----------+----+Example: Drop Duplicate Rows from PySpark DataFrame
# removing duplicate rows dataframe = dataframe.drop_duplicates() dataframe.show()
Output
+----------+---------+------+-------------+---+----------+----+
|first_name|last_name|gender|country |age|date |id |
+----------+---------+------+-------------+---+----------+----+
|Philip |Gent |Male |France |36 |2015-05-21|2587|
|Vishvajit |Rao |Male |India |26 |2022-04-10|1232|
|Kathleen |Hanner |Female|United States|25 |2017-10-15|1876|
|Ajay |Kumar |Male |India |27 |2018-04-10|1234|
|Dulce |Abril |Female|United States|32 |2017-10-15|1562|
|Vishvajit |Rao |Male |India |24 |2023-04-10|232 |
|Mara |Hashimoto|Female|Great Britain|25 |2016-08-16|1582|
+----------+---------+------+-------------+---+----------+----+PySpark DataFrame distinct() Method
It is a PySpark DataFrame method that is used to return only unique records from existing DataFrame to new DataFrame. It checks duplicate records in whole column names. It was first introduced in Spark 1.3.0. it does not take any parameters.
Example: Drop Duplicate Rows from PySpark DataFrame using distinct
from pyspark.sql import SparkSession
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating PySpark DataFrame
dataframe = spark.read.option('header', 'true').csv('sample_data.csv')
# removing duplicate rows
dataframe = dataframe.distinct()
# displaying
dataframe.show(truncate=False)
Output
+----------+---------+------+-------------+---+----------+----+
|first_name|last_name|gender|country |age|date |id |
+----------+---------+------+-------------+---+----------+----+
|Philip |Gent |Male |France |36 |2015-05-21|2587|
|Vishvajit |Rao |Male |India |26 |2022-04-10|1232|
|Kathleen |Hanner |Female|United States|25 |2017-10-15|1876|
|Ajay |Kumar |Male |India |27 |2018-04-10|1234|
|Dulce |Abril |Female|United States|32 |2017-10-15|1562|
|Vishvajit |Rao |Male |India |24 |2023-04-10|232 |
|Mara |Hashimoto|Female|Great Britain|25 |2016-08-16|1582|
+----------+---------+------+-------------+---+----------+----+👉PySpark DataFrame distinct() Reference:- Click Here
Related PySpark Articles
- How to convert PySpark Row To Dictionary
- PySpark Column Class with Examples
- PySpark Sort Function with Examples
- How to read CSV files using PySpark
- PySpark col() Function with Examples
- Convert PySpark DataFrame Column to List
- How to Write PySpark DataFrame to CSV
- How to Convert PySpark DataFrame to JSON
- How to Apply groupBy in Pyspark DataFrame
- Merge Two DataFrames in PySpark with the Same Column Names
- How to Count Null and NaN Values in Each Column in PySpark DataFrame?
Conclusion
So in Today’s article we have seen how to drop duplicate rows from PySpark DataFrame with the help of the dropDuplicates() method, drop_duplicates() function, and distinct() method with the help of the proper example.
You can use anyone as per your requirement if you want to check duplicate records in the whole column then you can go with all the methods and functions without any parameter but if you want to check duo duplicates records in a particular column then you will have to provide column names as a list inside dropDuplicates() and drop_duplicates().
If you found this article helpful, please share and keep visiting for further PySpark tutorials.
Frequently Asked Questions ( FAQs )
PySpark dropDuplicate() vs distinct()
Ans:- The dropDuplicate() method is a DataFrame method that drops the duplicate rows from the PySpark DataFrame and it accepts columns to check duplicate records in order to drop. The distinct() method is used to return the only unique rows from the PySpark DataFrame.
How do I delete duplicate rows in PySpark?
Ans:- PySpark distinct() method is used to drop/remove duplicate records from all the columns while dropDuplicates() drop the duplicate rows from selected column names.





