
Hi PySpark Developers, In this PySpark Recipe, you will see everything about how to merge two DataFrames in PySpark with different column names using various ways.
As PySpark Developers we must have knowledge about PySpark Merge two DataFrames with different columns because in real-life PySpark applications, Any time we have to join two PySpark DataFrame that might have different column names. Throughout this article, we are about to see a total of three ways to join two PySpark DataFrames with different-different column names.
PySpark provides some DataFrame methods to merge two or more DataFrame together but you have to remember one thing Data Type or Column All the DataFrame columns must be the same If the schema structure of all the DataFrame is not the same, first, we will have to make schema structure of all the DataFrames same then we can merge them together.
Let’s create two PySpark DataFrame with different column names.
Headings of Contents
- 1 Creating First PySpark DataFrame
- 2 Creating Second PySpark DataFrame
- 3 Add Missing Columns to Both PySpark DataFrames
- 4 Merge Two DataFrames in PySpark with Different Column Names
- 5 Merge Two DataFrames in PySpark with Different Column Names using the union() method
- 6 Merge Two DataFrames in PySpark with different column names using the unionAll() method
- 7 Merge Two DataFrames in PySpark with Different column Names using unionByName() method
- 8 Conclusion
Creating First PySpark DataFrame
Here, I have created my first PySpark DataFrame called dataframe_one. DataFrame has five column names like first_name, last_name, age, department, and salary. The data type or Column type of all the column names are string except age and salary.
from pyspark.sql import SparkSession
data1 = [
("Vikas", "Kumar", 25, "IT", 24000),
("Sachin", "Singh", 26, "HR", 23000),
("Hanshika", "Kumari", 15, "IT", 23000),
("Pankaj", "Singh", 28, "Finance", 25000),
("Shyam", "Singh", 24, "IT", 35000),
("Vinay", "Kumari", 25, "Finance", 24000),
("Vishal", "Srivastava", 21, "HR", 27000),
]
columns = ["first_name", "last_name", "age", "department", "salary"]
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating dataframe
dataframe_one = spark.createDataFrame(data1, columns)
# displaying dataframe
dataframe_one.show()
After executing the above code, The DataFrame will be like this.
+----------+----------+---+----------+------+
|first_name| last_name|age|department|salary|
+----------+----------+---+----------+------+
| Vikas| Kumar| 25| IT| 24000|
| Sachin| Singh| 26| HR| 23000|
| Hanshika| Kumari| 15| IT| 23000|
| Pankaj| Singh| 28| Finance| 25000|
| Shyam| Singh| 24| IT| 35000|
| Vinay| Kumari| 25| Finance| 24000|
| Vishal|Srivastava| 21| HR| 27000|
+----------+----------+---+----------+------+Let’s see the schema or data type of the above DataFrame using the printSchema() method.
dataframe_one.printSchema()
After applying printSchema() on the DataFrame, you will see a tree-like schema of DataFrame.
root
|-- first_name: string (nullable = true)
|-- last_name: string (nullable = true)
|-- age: long (nullable = true)
|-- department: string (nullable = true)
|-- salary: long (nullable = true)As you can see in the above schema data type of first_name, last_name and department is a string, and the data types of age and salary columns are long.
Creating Second PySpark DataFrame
Here, I have created my second PySpark DataFrame called dataframe_two. dataframe_two has two column names country and city. The data type or Column type of all the column names is a string.
from pyspark.sql import SparkSession
data2 = [
("India", "Noida"),
("India", "Lucknow"),
("India", "Mumbai"),
("USA", "San Diego"),
("USA", "New York"),
("India", "Delhi"),
("India", "Agara"),
]
columns = ["country", "city"]
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating dataframe
dataframe_two = spark.createDataFrame(data2, columns)
# displaying dataframe
dataframe_two.show()
# displaying schema
dataframe_two.printSchema()
After the successful execution of the above code, The DataFrame and schema will be like this.
+-------+---------+
|country| city|
+-------+---------+
| India| Noida|
| India| Lucknow|
| India| Mumbai|
| USA|San Diego|
| USA| New York|
| India| Delhi|
| India| Agara|
+-------+---------+
root
|-- country: string (nullable = true)
|-- city: string (nullable = true)As You can see columns name of both PySpark DataFrame dataframe_one and dataframe_two are different. Now it’s time to see multiple ways to merge two data frames in PySpark with different column names.
Important Note:- This will only be applicable for the union() and unionAll() methods. You have to remember one thing, If you have two PySpark DataFrame and you want to merge them together and those two DataFrames have different-different column names, in that scenario, you will have to add missing column names in both the PySpark DataFrame and then you can merge them. Before merging both the tables, The column names must be the same and their schema or Data Types also must be the same.
For example, In the dataframe_one table column names are first_name, last_name, age, department, and salary, and dataframe_two has column names are country and city, Therefore we have to add missing columns names like country and city in dataframe_one and first_name, last_name, age, department, and salary columns in dataframe_two with same schema type.
Add Missing Columns to Both PySpark DataFrames
To add missing values in the existing PySpark DataFrame we will use a PySpark built-in function called lit() and withColumns() DataFrame function.
Add Missing Columns in the first DataFrame
As we know, For dataframe_one, the column name country and city are missing. We will add a None value in both columns country and city because we don’t know what the will be values for these columns.
from pyspark.sql import SparkSession
from pyspark.sql.functions import lit
data1 = [
("Vikas", "Kumar", 25, "IT", 24000),
("Sachin", "Singh", 26, "HR", 23000),
("Hanshika", "Kumari", 15, "IT", 23000),
("Pankaj", "Singh", 28, "Finance", 25000),
("Shyam", "Singh", 24, "IT", 35000),
("Vinay", "Kumari", 25, "Finance", 24000),
("Vishal", "Srivastava", 21, "HR", 27000),
]
columns = ["first_name", "last_name", "age", "department", "salary"]
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating dataframe
dataframe_one = spark.createDataFrame(data1, columns)
# adding country and city column name
dataframe_one = dataframe_one.withColumns(
{
"country": lit(None),
"city": lit(None)
}
)
# displaying dataframe
dataframe_one.show()
After adding country and city the final data frame will be like this.
+----------+----------+---+----------+------+-------+----+
|first_name| last_name|age|department|salary|country|city|
+----------+----------+---+----------+------+-------+----+
| Vikas| Kumar| 25| IT| 24000| null|null|
| Sachin| Singh| 26| HR| 23000| null|null|
| Hanshika| Kumari| 15| IT| 23000| null|null|
| Pankaj| Singh| 28| Finance| 25000| null|null|
| Shyam| Singh| 24| IT| 35000| null|null|
| Vinay| Kumari| 25| Finance| 24000| null|null|
| Vishal|Srivastava| 21| HR| 27000| null|null|
+----------+----------+---+----------+------+-------+----+Add Missing in Second PySpark DataFrame
For dataframe_two first_name, last_name, age, department and salary are the missing columns, We will also add a None value for these column names.
from pyspark.sql import SparkSession
from pyspark.sql.functions import lit
data2 = [
("India", "Noida"),
("India", "Lucknow"),
("India", "Mumbai"),
("USA", "San Diego"),
("USA", "New York"),
("India", "Delhi"),
("India", "Agara"),
]
columns = ["country", "city"]
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating dataframe
dataframe_two = spark.createDataFrame(data2, columns)
# adding first_name, last_name, age, department and salary
dataframe_two = dataframe_two.withColumns(
{
"first_name": lit(None),
"last_name": lit(None),
"age": lit(None),
"department": lit(None),
"salary": lit(None)
}
)
# rearrange column name according to first PySpark DataFrame
dataframe_two = dataframe_two.select("first_name", "last_name", "age", "department", "salary", "country", "city")
# display PySpark DataFrame
dataframe_two.show()
After adding missing column names in dataframe_two the data frame will be like this.
+----------+---------+----+----------+------+-------+---------+
|first_name|last_name| age|department|salary|country| city|
+----------+---------+----+----------+------+-------+---------+
| null| null|null| null| null| India| Noida|
| null| null|null| null| null| India| Lucknow|
| null| null|null| null| null| India| Mumbai|
| null| null|null| null| null| USA|San Diego|
| null| null|null| null| null| USA| New York|
| null| null|null| null| null| India| Delhi|
| null| null|null| null| null| India| Agara|
+----------+---------+----+----------+------+-------+---------+Merge Two DataFrames in PySpark with Different Column Names
PysPark provides some DataFrame methods that are used to join two or more tables together. Here, I have given all the methods along with descriptions.
- union():- It is the PySpark DataFrame method that is used to combine two PySpark DataFrame together. It always applies on top of Dataframe and also takes DataFrame as a parameter in order to combine them. Column position must be the same in both PySpark DataFrames.
- unionAll():- It is the PySpark DataFrame method that is used to combine two PySpark DataFrames together. It always applies on top of Dataframe and also takes DataFrame as a parameter in order to combine them. Column position must be the same in both PySpark DataFrames.
- unionByName():- unionByName() method is a little bit different from the union() and unionAll() because it merges the DataFrames by the name of the columns, not by position.
Merge Two DataFrames in PySpark with Different Column Names using the union() method
The union() method is a PySpark DataFrame method that is used to combine two PySpark DataFrame together and return a new DataFrame.It is similar to Union all in the SQL ( Structure Query Language ). It applies on top of PySpark DataFrame and takes another DataFrame as a parameter. Remember, during the use of the union() method column position in both the PySpark DataFrame must be the same.
Example:- PySpark Merge Two DataFrame using union() method:
from pyspark.sql import SparkSession
from pyspark.sql.functions import lit
data1 = [
("Vikas", "Kumar", 25, "IT", 24000),
("Sachin", "Singh", 26, "HR", 23000),
("Hanshika", "Kumari", 15, "IT", 23000),
("Pankaj", "Singh", 28, "Finance", 25000),
("Shyam", "Singh", 24, "IT", 35000),
("Vinay", "Kumari", 25, "Finance", 24000),
("Vishal", "Srivastava", 21, "HR", 27000),
]
columns = ["first_name", "last_name", "age", "department", "salary"]
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating dataframe
dataframe_one = spark.createDataFrame(data1, columns)
# adding country and city column name
dataframe_one = dataframe_one.withColumns(
{
"country": lit(None),
"city": lit(None)
}
)
# second DataFrame
data2 = [
("India", "Noida"),
("India", "Lucknow"),
("India", "Mumbai"),
("USA", "San Diego"),
("USA", "New York"),
("India", "Delhi"),
("India", "Agara"),
]
columns = ["country", "city"]
# creating dataframe
dataframe_two = spark.createDataFrame(data2, columns)
# adding first_name, last_name, age, department and salary
dataframe_two = dataframe_two.withColumns(
{
"first_name": lit(None),
"last_name": lit(None),
"age": lit(None),
"department": lit(None),
"salary": lit(None)
}
)
# rearrange column name according to first PySpark DataFrame
dataframe_two = dataframe_two.select("first_name", "last_name", "age", "department", "salary", "country", "city")
# merge both the tables or PySpark DataFrame
dataframe_one.union(dataframe_two).show()
After merging both PySpark DataFrame using the union() method, The final Dataframe will be:
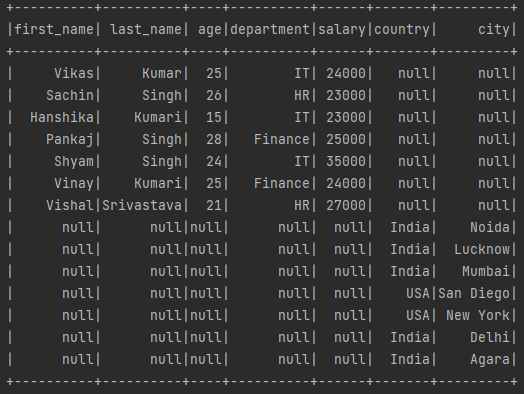
👉 PySpark DataFrame union() method Reference:- Click Here
Merge Two DataFrames in PySpark with different column names using the unionAll() method
The unionAll() method is a also PySpark DataFrame method that is used to combine two PySpark DataFrame together and return a new DataFrame.It is similar to UNION ALL in the SQL ( Structure Query Language ). It applies on top of PySpark DataFrame and takes another DataFrame as a parameter. The position of both PySpark DataFrame must be the same.
Example:- PySpark Merge Two DataFrame using unionAll() method:
from pyspark.sql import SparkSession
from pyspark.sql.functions import lit
data1 = [
("Vikas", "Kumar", 25, "IT", 24000),
("Sachin", "Singh", 26, "HR", 23000),
("Hanshika", "Kumari", 15, "IT", 23000),
("Pankaj", "Singh", 28, "Finance", 25000),
("Shyam", "Singh", 24, "IT", 35000),
("Vinay", "Kumari", 25, "Finance", 24000),
("Vishal", "Srivastava", 21, "HR", 27000),
]
columns = ["first_name", "last_name", "age", "department", "salary"]
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating dataframe
dataframe_one = spark.createDataFrame(data1, columns)
# adding country and city column name
dataframe_one = dataframe_one.withColumns(
{
"country": lit(None),
"city": lit(None)
}
)
# second DataFrame
data2 = [
("India", "Noida"),
("India", "Lucknow"),
("India", "Mumbai"),
("USA", "San Diego"),
("USA", "New York"),
("India", "Delhi"),
("India", "Agara"),
]
columns = ["country", "city"]
# creating dataframe
dataframe_two = spark.createDataFrame(data2, columns)
# adding first_name, last_name, age, department and salary
dataframe_two = dataframe_two.withColumns(
{
"first_name": lit(None),
"last_name": lit(None),
"age": lit(None),
"department": lit(None),
"salary": lit(None)
}
)
# rearrange column name according to first PySpark DataFrame
dataframe_two = dataframe_two.select("first_name", "last_name", "age", "department", "salary", "country", "city")
# merge both the tables or PySpark DataFrame
dataframe_one.unionAll(dataframe_two).show()
After merging both PySpark DataFrame using unionAll() method, The final Dataframe will be:
PySpark DataFrame unionAll() method Reference:- Click Here
Merge Two DataFrames in PySpark with Different column Names using unionByName() method
The unionByName() method is a also PySpark DataFrame method that is used to combine two PySpark DataFrame together and return a new DataFrame.It is a bit different from union() and unionAll() because it takes an additional parameter called allowMissingColumns which accepts True or False, By default, it is set to False.
When it is set to True then it will fill the null values of the columns that are not matching in both PySpark DataFrame, but the column which you want to use for merging should be the same in both PySpark DataFrame. It applies on top of PySpark DataFrame and takes another DataFrame as a parameter.
Unlike union() and unionAll(), It’s not mandatory to add missing column names and maintain the position of column names in both the DataFrame, It will maintain automatically detect the missing column in both tables and add them. For a better understanding, see the below example.
Example:- PySpark Merge Two DataFrame using unionByName() method:
from pyspark.sql import SparkSession
data1 = [
("Vikas", "Kumar", 25, "IT", 24000),
("Sachin", "Singh", 26, "HR", 23000),
("Hanshika", "Kumari", 15, "IT", 23000),
("Pankaj", "Singh", 28, "Finance", 25000),
("Shyam", "Singh", 24, "IT", 35000),
("Vinay", "Kumari", 25, "Finance", 24000),
("Vishal", "Srivastava", 21, "HR", 27000),
]
columns = ["first_name", "last_name", "age", "department", "salary"]
# creating spark session
spark = SparkSession.builder.appName("testing").getOrCreate()
# creating dataframe
dataframe_one = spark.createDataFrame(data1, columns)
# second DataFrame
data2 = [
("India", "Noida"),
("India", "Lucknow"),
("India", "Mumbai"),
("USA", "San Diego"),
("USA", "New York"),
("India", "Delhi"),
("India", "Agara"),
]
columns = ["country", "city"]
# creating dataframe
dataframe_two = spark.createDataFrame(data2, columns)
# merge both the tables or PySpark DataFrame
dataframe_one.unionByName(dataframe_two, allowMissingColumns=True).show()
After merging both PySpark DataFrame using the unionByName() method, The final Dataframe will be:
Note:- All the DataFrame methods like union(), unionAll(), and unionByName() do not remove duplicate rows by default. If you want to remove duplicate rows then you have to use the distinct() method on top of the final data frame. As You can see below.
👉PySpark DataFrame unionByName() method:- Click Here
# remove duplicate rows unique_dataframe = final_dataframe.distinct() # displaying DataFrame unique_dataframe.show()
👉PySpark DataFrame distinct() method:- Click Here
Related PySpark Tutorials
- How to convert PySpark Row To Dictionary
- PySpark Column Class with Examples
- PySpark Sort Function with Examples
- How to read CSV files using PySpark
- PySpark col() Function with Examples
- Convert PySpark DataFrame Column to List
- How to Write PySpark DataFrame to CSV
- How to Convert PySpark DataFrame to JSON
- How to Apply groupBy in Pyspark DataFrame
- Merge Two DataFrames in PySpark with the Same Column Names
- How to Count Null and NaN Values in Each Column in PySpark DataFrame?
- How to Drop Duplicate Rows from PySpark DataFrame
Conclusion
So throughout this PySpark tutorial, we have successfully covered PySpark DataFrame’s union(), unionAll(), and unionByName() methods in order to merge Two DataFrames in PySpark DataFrame with different column names.
You can use any one of them at your convenience. This is going to be very helpful when you are going to load data from different-different sources that have different difference column names and finally, you want to merge them in order to perform some required Transformations and actions.
If you found this article helpful, please share and keep visiting for further PySpark tutorials.





