In this article, you will learn everything about how to drop duplicate rows in Pandas DataFrame with the help of the example. We will delete duplicate rows based on the multiple conditions using proper examples.
This is one of the most important questions from an interview point of view, personally, I have faced this question multiple times in Data analysis and data engineering interviews. If you are a Data analysis or data engineer then this is going to be very helpful for you.
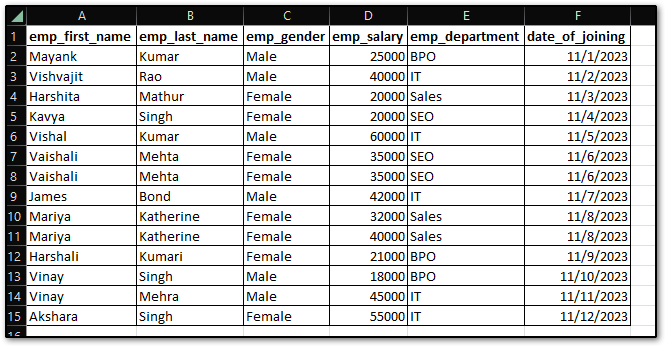
I have prepared a Sample CSV dataset with some duplicate rows, as you can see below. Throughout this article, we will use this dataset and one more thing I want to say, Here I am using Jupyter Notebook to write the code, you can go with any code editor at your convenience.
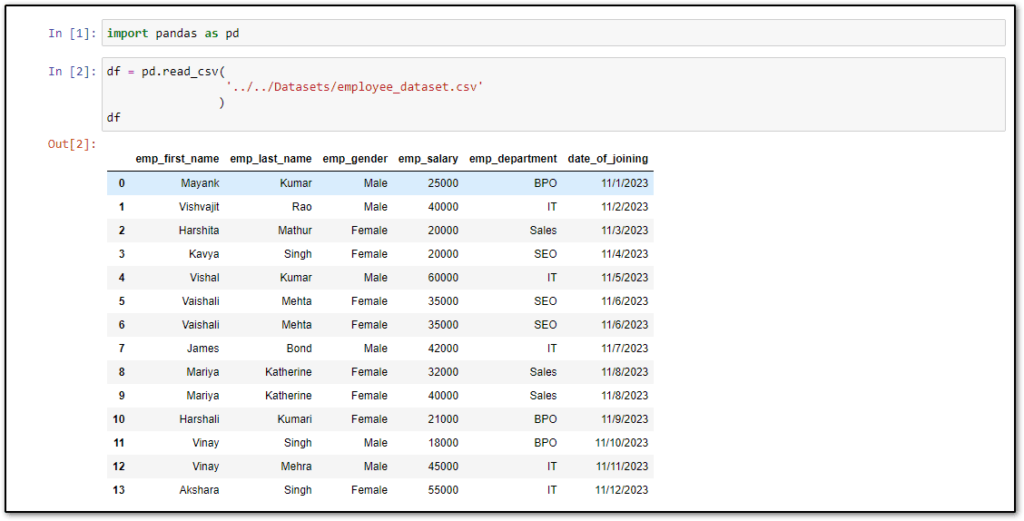
Let’s load the above CSV dataset into Pandas DataFrame using the read_csv() method, so that we can perform operations on top of DataFrame.
To delete duplicate rows from the Pandas DataFrame, We will use the drop_duplicates() method which is a Pandas DataFrame method that will apply only on top of the DataFrame.
Before going too deep into this article, Let’s understand about drop_duplicates() method.
Headings of Contents
Pandas DataFrame drop_duplicates() Method
drop_duplicates() is a DataFrame method that is used to drop duplicate rows in Pandas DataFrame.It always applies on top of the Pandas DataFrame.
Syntax:
DataFrame.drop_duplicates(subset=None, *, keep='first', inplace=False, ignore_index=False
As you can see, drop_duplicates() accepts various parameters, Let’s understand all of them one by one.
Parameters:
- subset: Column labels or sequence of labels, Optional. By default, it uses all the column names to identify duplicate values.
- keep: it should be either ‘first’, ‘last’, or false. Default is first.
- first:- Drop all the duplicates except the first.
- last:- Drop all the duplicates except the last.
- false:- drop all the duplicates.
- inplace: It takes True or False. If True is assigned then it will modify the existing DataFrame otherwise it will return a new DataFrame.
- ignore_index: It takes True or False, By default it accepts False.
Now, that we have successfully covered the Pandas DataFrame drop_duplicates() method, it is time to see examples of deleting duplicate rows from the Pandas DataFrame.
How to Drop Duplicate Rows in Pandas DataFrame
Let’s see some examples of dropping duplicate rows in Pandas DataFrame with different examples and for each example, we will see all the parameters of the drop_duplicate() method.
Drop all duplicate rows in Pandas DataFrame
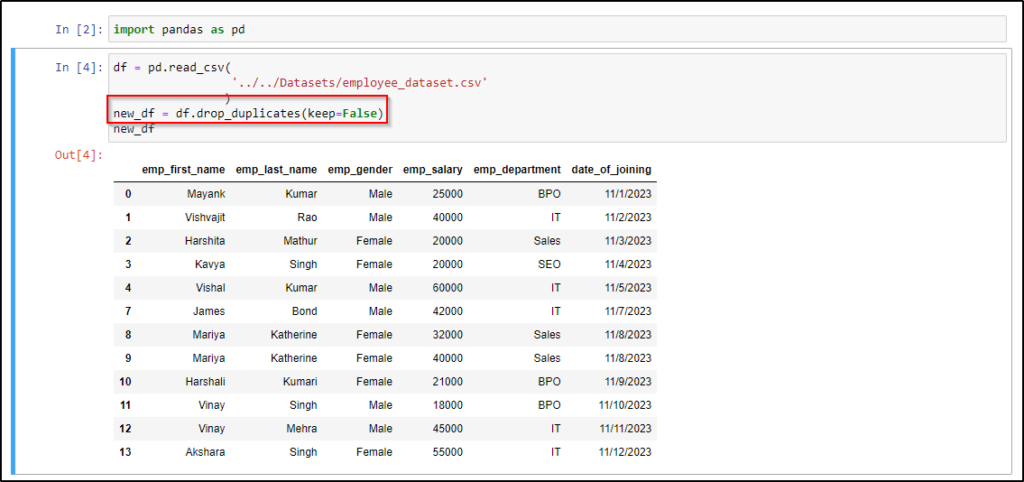
In the above DataFrame, you can see values of all the columns are the same in rows number 5 and 6 which means both are duplicate rows and now we want to delete both of them. We will use the drop_duplicates() method along with the keep=False parameter, By default, the drop_duplicates() method checks the duplicity of data in all the columns.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employee_dataset.csv'
)
new_df = df.drop_duplicates(keep=False)
print(new_df)
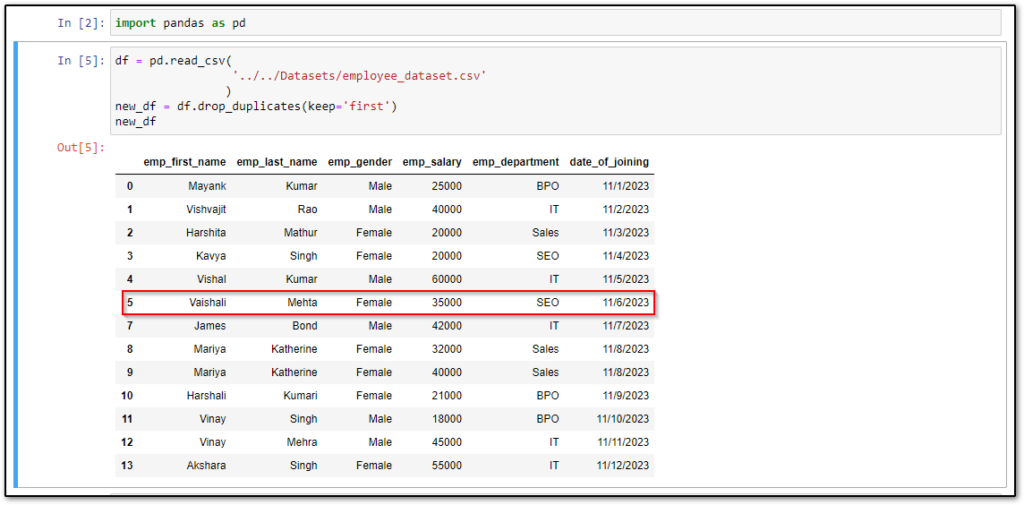
Drop Duplicate Rows in Pandas DataFrame Except for First
Sometimes we want to delete all the duplicate rows except the first one. For example, in the above example, we have deleted both rows 5 and 6 but if want to keep the first one means row number 5 in that case we will use the keep=’first’ in the drop_duplicates() method.
Let’s see.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employee_dataset.csv'
)
new_df = df.drop_duplicates(keep='first')
print(new_df)
Drop Duplicate Rows in Pandas DataFrame Except Last
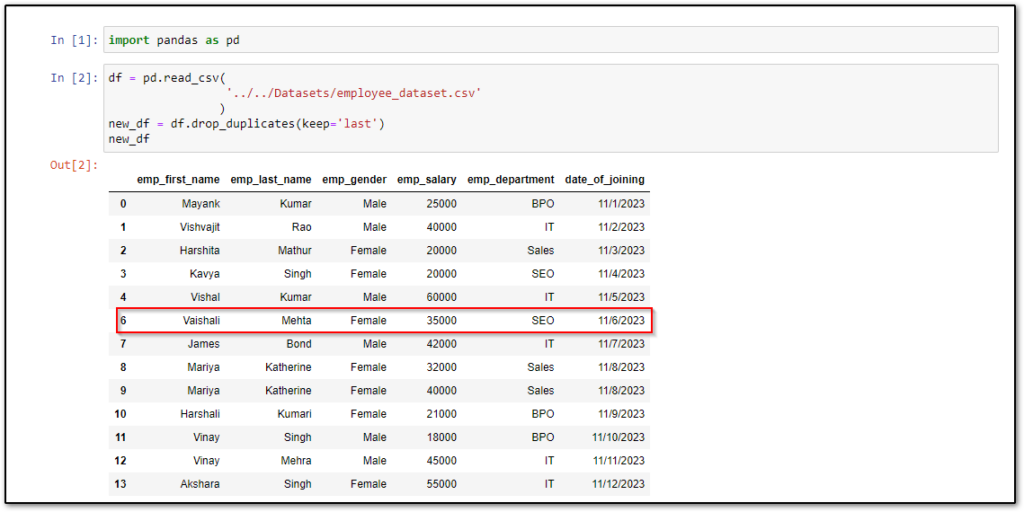
Same as the above example, sometimes we want to keep the last duplicate row except all, in that scenario, we need to pass the keep=’last’ in the drop_duplicates() method.
For example, In the above sample Pandas DataFrame, rows number 5 and 6 are duplicates but here I want to delete all duplicate rows except the last row means row number 6.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employee_dataset.csv'
)
new_df = df.drop_duplicates(keep='last')
print(new_df)
Drop duplicate rows based on the specific column
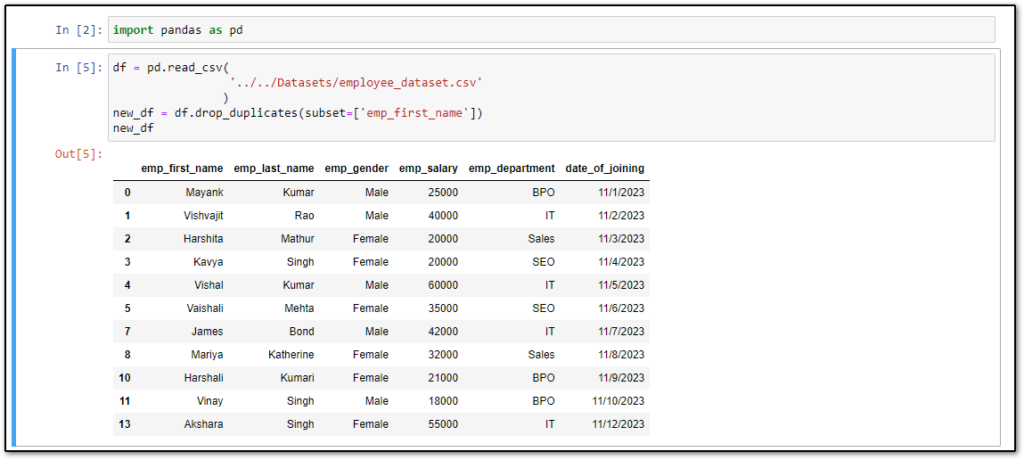
As you can see in the sample DataFrame, values of all the columns in rows number 5 and 6 are the same but sometimes we want to check the duplicate of values in some specific column then you can pass all those column names as lists in drop_duplicates() method as the first parameter.
In the sample DataFrame, the value of the emp_first_name column is the same in row number 5, 6 and 11, 12, and now want to check the duplicity of values in only the emp_first_name column and delete all of them.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employee_dataset.csv'
)
new_df = df.drop_duplicates(subset=['emp_first_name'])
print(new_df)
Pandas DataFrame drop_duplicates() method with inplce parameter
In all the above examples, we didn’t use inplace parameter in the drop_duplicates() method.inplace parameter allows us to change the existing Panadas DataFrame or return a new df. If inplace is set to True then it will change the existing Pandas DataFrame otherwise it will return the new Pandas DataFrame.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employee_dataset.csv'
)
df.drop_duplicates(subset=['emp_first_name'], inplace=True)
print(df)
So this is how you can delete duplicate rows from Pandas DataFrame, Now let’s wrap up this article here. I hope you don’t have any confusion regarding this article.
Useful Pandas Articles:
- How To Add a Column in Pandas Dataframe
- How to Replace Column Values in Pandas DataFrame
- How to Convert Excel to JSON in Python
- How to convert DataFrame to HTML in Python
- How to Delete a Column in Pandas DataFrame
- How to convert SQL Query Result to Pandas DataFrame
- How to Convert Dictionary to Excel in Python
- How to Convert Excel to Dictionary in Python
- How to Rename Column Name in Pandas DataFrame
- How to Get Day Name from Date in Pandas DataFrame
Conclusion
Throughout this article, we have seen how to drop duplicate rows in Pandas DataFrame with the help of multiple examples. Pandas drop_duplicates() method takes multiple parameters which you can use according to your requirements.
To delete all the duplicate values you will need to pass False in the keep parameter, pass ‘first’ to keep the first row, and pass ‘last’ to keep the last row.
If you found this article helpful, please share and keep visiting for further Pandas tutorials.
Happy Coding….