In this Pandas tutorial, we will explore all about the Pandas groupby() method with the help of the examples. Pandas groupby() is very similar to the Group by in SQL that is used to group the result set according to similar values and apply aggregate functions like sum, min, max, avg, etc on a group of the result set.
If you are familiar with Group By in SQL then you can easily understand Group By in Pandas DataFrame.
Pandas provides a DataFrame groupby() method that is used to group the result set based on the passed columns. Before going to deep dive into this article, Let’s see all about the Pandas groupby() method.
Headings of Contents
Pandas DataFrame groupby() Method
groupby() is a DataFrame method that is used to grouping the Pandas DataFrame by mapper or series of columns. The groupby() method splits the objects into groups, applying an aggregate function on the groups and finally combining the result set.
Syntax of Pandas groupby() Method:
This is the syntax of the Pandas groupby() method.
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True)
Parameter of groupby() Method:
The Pandas groupby() Method accepts some keyword argument parameters that can be used as per requirement.
by:- Required, A labels, A list of labels or a function used to specifiy how to group the DataFrame.
axis:- {0 for 'Index', 1 for 'column'}. Default is 0. For the series, this parameter is unused and by default set to 0.
level:- int, level name, If the axis is multiplex, group by particular level or levels. Do not specify both by and level.
as_index:- Boolean, Default is True.Return the objects with group lavels.
sort:- Boolean, Default is True. It is used to sort the group keys.You can get better performance by turning this off.
group_keys:- Boolean, Default is True. Set to False if the result should not add the groups to the index.
observed:- It has been deprecated from Pandas version 2.1.0.
dropna:- Boolean, default is True. If True and if group keys contains NA value, NA values together with rows and columns will be droped.
Now let’s see how to use group in Pandas DataFrame with the help of some examples.
How to use GroupBy in Pandas DataFrame
For a demonstration of this article, I have prepared a sample CSV dataset along with some dummy data. Throughout this article, we are about to use this sample CSV dataset.
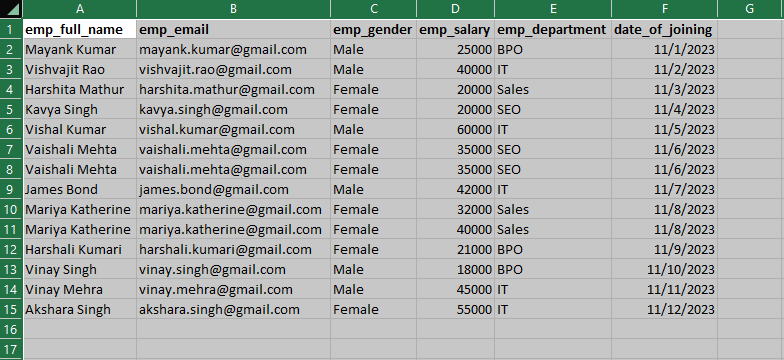
I have loaded the above Sample CSV dataset into Pandas DataFrame with the help of the Pandas read_csv() method.
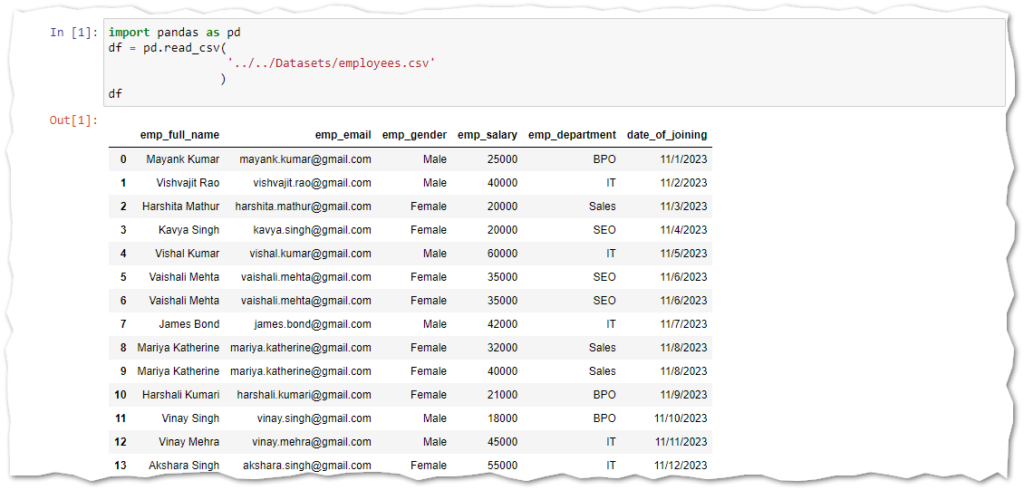
Group By Department in Pandas DataFrame
As you can see in the above Pandas DataFrame, we have one emp_department column that has a department for each employee. Now we want to group the Pandas DataFrame based on the department and perform some aggregate functions on each group.
To apply the aggregate function, we can use the agg() function along with the aggregate function otherwise we can use the corresponding aggregate function directly on groupby() object.
The most common aggregate functions are sum(), mean(), count(), min(), max(), size(), median() and var().
sum() aggregate function:
The sum() function is used to add the total salary of all the employees within a department. For example, I want to get the total salary of employees in a particular department.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employees.csv'
)
x = df.groupby(['emp_department']).sum()
x[['emp_salary']]
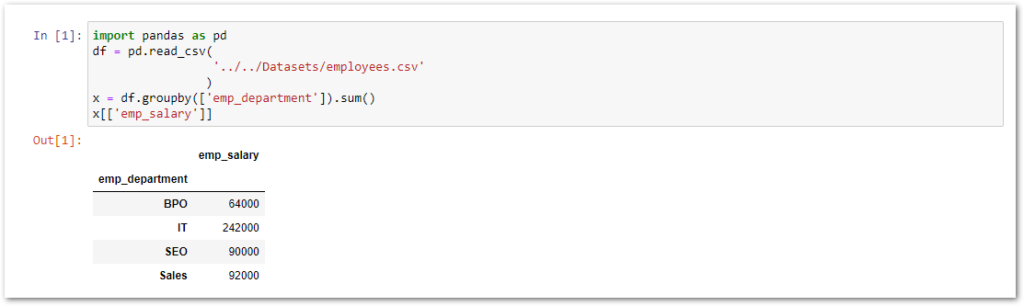
count() aggregate function:
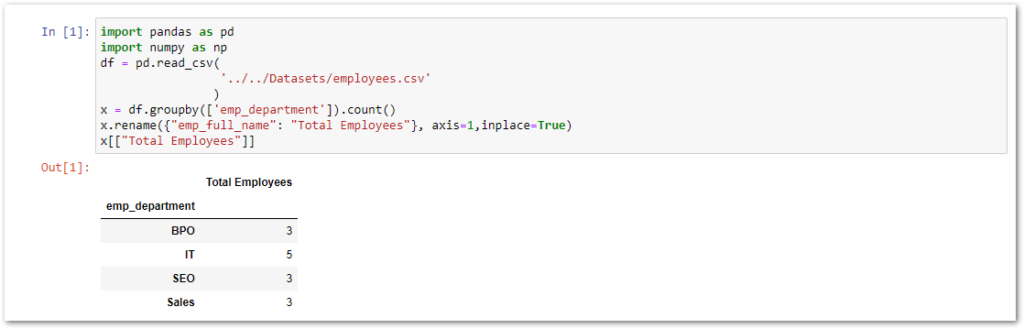
The count() aggregate function is used to return the total number of rows in each group. For example, I want to get the total number of employees in each department.
import pandas as pd
import numpy as np
df = pd.read_csv(
'../../Datasets/employees.csv'
)
x = df.groupby(['emp_department']).count()
x.rename({"emp_full_name": "Total Employees"}, axis=1,inplace=True)
x[["Total Employees"]]
How does Pandas Groupby work?
Pandas groupby() Method performs three operations behind the scenes. Three operations are listed below.
- Splitting:- Splitting the original object into groups based on the defined criteria.
- Applying:- Applying aggregate function on each group.
- Combining:- Combining the results.
This process is also called a split-apply-combine chain.
Let’s understand all the above operations step by step with the help of the examples.
Splitting the original objects into groups:
When we call the Pandas groupby() method on the top of the Pandas DataFrame.The groupby() method splits the objects into groups based on predefined criteria. The groupby() functions map the labels to the names of the groups.
For example, we are grouping the data based on the emp_department.
groups = df.groupby('emp_department')We can also group the data based on the multiple-column names.
groups = df.groupby(['emp_gender', 'emp_department'])The groupby() function always returns a groupby object which contains multiple groups.
We can get all the groups by iterating over the groupby() object.
Let’s use Python for loop to iterate each item of the groupby object. Here, I am trying to group the Pandas DataFrame based on the emp_department column.
import pandas as pd
import numpy as np
df = pd.read_csv(
'../../Datasets/employees.csv'
)
groups = df.groupby(['emp_department'])
for group_name, data in groups:
print("Group Name is:- ", group_name)
print("-------------------------")
print("Group Data:- \n\n", data)
The Output will be:
Group Name is:- ('BPO',)
-------------------------
Group Data:-
emp_full_name emp_email emp_gender emp_salary \
0 Mayank Kumar [email protected] Male 25000
10 Harshali Kumari [email protected] Female 21000
11 Vinay Singh [email protected] Male 18000
emp_department date_of_joining
0 BPO 11/1/2023
10 BPO 11/9/2023
11 BPO 11/10/2023
Group Name is:- ('IT',)
-------------------------
Group Data:-
emp_full_name emp_email emp_gender emp_salary \
1 Vishvajit Rao [email protected] Male 40000
4 Vishal Kumar [email protected] Male 60000
7 James Bond [email protected] Male 42000
12 Vinay Mehra [email protected] Male 45000
13 Akshara Singh [email protected] Female 55000
emp_department date_of_joining
1 IT 11/2/2023
4 IT 11/5/2023
7 IT 11/7/2023
12 IT 11/11/2023
13 IT 11/12/2023
Group Name is:- ('SEO',)
-------------------------
Group Data:-
emp_full_name emp_email emp_gender emp_salary \
3 Kavya Singh [email protected] Female 20000
5 Vaishali Mehta [email protected] Female 35000
6 Vaishali Mehta [email protected] Female 35000
emp_department date_of_joining
3 SEO 11/4/2023
5 SEO 11/6/2023
6 SEO 11/6/2023
Group Name is:- ('Sales',)
-------------------------
Group Data:-
emp_full_name emp_email emp_gender emp_salary \
2 Harshita Mathur [email protected] Female 20000
8 Mariya Katherine [email protected] Female 32000
9 Mariya Katherine [email protected] Female 40000
emp_department date_of_joining
2 Sales 11/3/2023
8 Sales 11/8/2023
9 Sales 11/8/2023 Access Specific Group:
Pandas groupby() object has a special method called get_group() which takes the group name parameter and returns the data in the form of Pandas DataFrame.
Each department name represents a group name, For example, I want to select the IT group, and Then we will pass the IT name in the get_group() method.
Let’s see.
import pandas as pd
import numpy as np
df = pd.read_csv(
'../../Datasets/employees.csv'
)
groups = df.groupby(['emp_department'])
groups.get_group('IT')
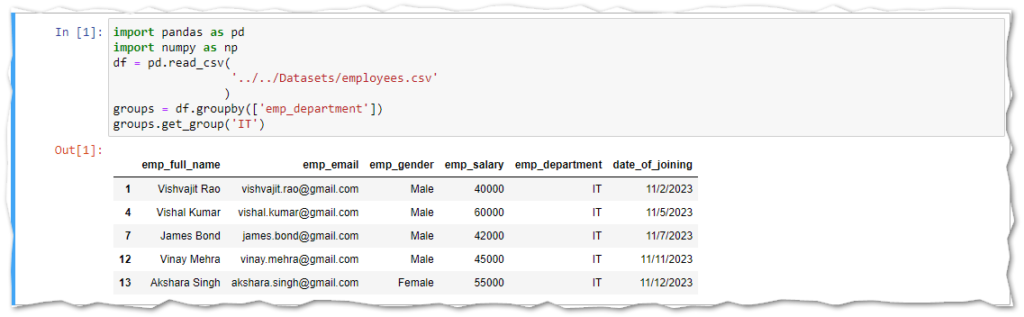
This is how you can get single group information in the form of Pandas DataFrame by using the get_group() method. Now, let’s see how we can use aggregate functions.
Applying Aggregate Functions
After splitting the original objects into groups, we can apply aggregate functions on top of the GroupBy object even if we can apply aggregate functions by each group.
Let’s apply aggregate functions on the GroupBy object.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employees.csv'
)
groups = df.groupby(['emp_department'])
groups.max()
The max() aggregate function returns the maximum salary of each department.
aggregate functions can also be applied to a single group.
Let’s apply the median() aggregate function to the IT group.
import pandas as pd
df = pd.read_csv(
'../../Datasets/employees.csv'
)
groups = df.groupby(['emp_department'])
groups.get_group('IT')['emp_salary'].median()

This is the way you can use aggregate functions on GroupBy objects or single groups.
Combining
This is the last step in the GroupBy process. After applying aggregate functions on each group it combines the result set of all the groups into a single DataFrame.This stage is performed by the Pandas itself.
This is how Pandas GroupBy works.
Helpful Pandas Articles
- How to convert Dictionary to CSV
- How to convert YML to Dictionary
- How to convert Excel to Dictionary
- How to Convert String to DateTime in Python
- How to Sort the List Of Dictionaries By Value in Python
- How To Add a Column in Pandas Dataframe
- How to Replace Column Values in Pandas DataFrame
- How to Convert Excel to JSON in Python
- How to Drop Duplicate Rows in Pandas DataFrame
- How to convert DataFrame to HTML in Python
- How to Delete a Column in Pandas DataFrame
- How to convert SQL Query Result to Pandas DataFrame
- How to Convert Dictionary to Excel in Python
- How to Convert Excel to Dictionary in Python
- How to Rename Column Name in Pandas DataFrame
- How to Get Day Name from Date in Pandas DataFrame
- How to Split String in Pandas DataFrame Column
👉 Pandas DataFrame groupby() Method Documentation:- Click Here
Conclusion
So during this article, we have seen how to use groupby in Pandas DataFrame along with some examples and we have seen the working of Pandas groupby() method. This is one of the useful features in Data Engineering and Data Analysis that we must know Pandas GroupBy method.
If you found this article helpful, Please share and keep visiting for further Pandas tutorials.





