
In this PySpark tutorial, You will learn all about PySpark Normal Built-in functions with the help of the proper examples so that you can use all the useful PySpark standard built-in functions in your real-life spark application.
PySpark built-in functions are the pre-defined functions in PySpark that come with PySpark by default and all the built-in functions have been written inside pyspark.sal.functions package, That’s why you have to import built-in functions from pyspark.sql.functions module.
Headings of Contents
Why do we need to use PySpark’s Built-in functions?
Built-in functions in any programming language like Java, Python, R, C, C++, etc are the most useful functions that come with programming languages by default. Sames as PySpark also comes with numerous built-in functions which easy to work with PySpark.
For example, PySpark provides some string built-in functions which will only be applicable to string kind of value, Same as PySpark provides DateTime functions that will be applicable to date time kind of value.
We don’t have to write a custom function to perform operations on top of RDD and DataFrame, However, PySpark provides the facility to write our own custom functions called UDF which stands for User Defined Functions.
In a later tutorial, we will see how we can use UDF in PySpark, as of now we will only focus on normal PySpark Built-in functions.
Let’s create a simple PySpark DataFrame so that we can use built-in functions on top of that.
Creating PySpark DataFrame
I have written a simple PySpark code to generate a PySpark data frame. You can follow this code base to create DataFrame.
PySpark DataFrame is nothing but it is a distributed collection of data and it same as an SQL table-like structure that contains data in the form of rows and columns and we can perform almost all the functionality of SQL on top of PySpark DataFrame.
from pyspark.sql import SparkSession
# list of tuples
data = [
("1", "Vishvajit", "Rao", None, "BCA10"),
("2", "Harsh", "Goal", "2021-12-10", "BT101"),
("3", "Pankaj", None, "2020-06-29", "BCA10"),
("4", "Pranjal", "Rao", None, "BT101"),
("5", "Ritika", "Kumari", "2019-11-26", "MT101"),
("6", "Diyanshu", "Saini", "2023-01-01", "BCA10"),
("7", "Pratiksha", None, "2018-07-10", "MT101"),
("8", "Shailja", "Srivastava", None, "BT101"),
]
# columns
column_names = [
"serial_number",
"first_name",
"last_name",
"date_of_admission",
"course_code"
]
# creating spark session
spark = SparkSession.builder.appName("www.programmingfunda.com").getOrCreate()
# creating DataFrame
df = spark.createDataFrame(data=data, schema=column_names)
# displaying
df.show(truncate=False)
Output
After executing the above code the output will be like this.
+-------------+----------+----------+-----------------+-----------+
|serial_number|first_name|last_name |date_of_admission|course_code|
+-------------+----------+----------+-----------------+-----------+
|1 |Vishvajit |Rao |null |BCA10 |
|2 |Harsh |Goal |2021-12-10 |BT101 |
|3 |Pankaj |null |2020-06-29 |BCA10 |
|4 |Pranjal |Rao |null |BT101 |
|5 |Ritika |Kumari |2019-11-26 |MT101 |
|6 |Diyanshu |Saini |2023-01-01 |BCA10 |
|7 |Pratiksha |null |2018-07-10 |MT101 |
|8 |Shailja |Srivastava|null |BT101 |
+-------------+----------+----------+-----------------+-----------+Let me break down the above code to know what’s going on with this code.
- First, I imported the SparkSession class from the pyspark.sql package.
- Second, I have defined a list of tuples and each tuple represents some information about the student like serial_number, first_name, last_name, date_of_admission, and course_code.
- Third, I have defined a Python list that contained column names (serial_number, first_name, last_name, date_of_admission, course_code).
- Fourth, I have created a spark session object using SparkSession.builder.appName(“testing”).getOrCreate().
- SparkSession represents the class name that is defined inside the PySpark SQL package.
- builder is the attribute of the SparkSession class which has a Builder class to initiate the spark session.
- appName() is a method that is used to provide the name of the spark application, In my case the application name is www.programmingfunda.com.
- getOrCreate() is also a method that is used to get the existing spark session or create a new spark session if the spark session is not available.
- Fifth, I have accessed the createDataFrame() method using spark in order to create a new PySpark DataFrame. I have passed the two arguments in createDataFrame(), First is a list of tuples, second is column names as a list. The createDataFrame() method returns a new DataFrame.
- Sixth, I have used the DataFrame show() method that is used to show the DataFrame-like table structure.
Now it’s time to explore PySpark Normal Built-in functions with the help of an example.
PySpark Normal Built-in functions
Let’s explore all the PySpark Normal Built-in functions one by one with the help of examples.

col(col)
The col() function takes a parameter that indicates the column name and PySpark DataFrame and it returns the object of PySpark Column class. To use the col() function we will have to import it from pyspark.sql.functions because it has been defined there.
For example, I am about to select only first_name and last_name from PySpark DataFrame using the col() function.
from pyspark.sql.functions import col
# selecting only first_name and last_name from PySpark DataFrame
df = df.select(col('first_name'), col('last_name'))
Output
+----------+----------+
|first_name|last_name |
+----------+----------+
|Vishvajit |Rao |
|Harsh |Goal |
|Pankaj |null |
|Pranjal |Rao |
|Ritika |Kumari |
|Diyanshu |Saini |
|Pratiksha |null |
|Shailja |Srivastava|
+----------+----------+column(col)
The column() functions work the same as the col() functions.
For instance, I am about to select the first_name, last_name, and course_code of students.
from pyspark.sql.functions import column
# selecting only first_name and last_name from PySpark DataFrame
df = df.select(column('first_name'), column('last_name'), column('course_code'))
# displaying
df.show(truncate=False)
Output
+----------+----------+-----------+
|first_name|last_name |course_code|
+----------+----------+-----------+
|Vishvajit |Rao |BCA10 |
|Harsh |Goal |BT101 |
|Pankaj |null |BCA10 |
|Pranjal |Rao |BT101 |
|Ritika |Kumari |MT101 |
|Diyanshu |Saini |BCA10 |
|Pratiksha |null |MT101 |
|Shailja |Srivastava|BT101 |
+----------+----------+-----------+lit(col)
The lit() function is used to create a column with a literal value. We can pass the constant value as well as the column name inside the lit() function.
Let’s see both of them one by one.
Example: Using lit() function with the literal value
In this example, I have added a column named country which contained India as a value because in my case all the students belong to the country India.
from pyspark.sql.functions import lit
# adding a column country along with India value
df = df.withColumn('country', lit('India'))
# displaying
df.show(truncate=False)
Output

broadcast(df)
The broadcast() function is one of the most useful functions in PySpark in order to perform broadcast joins. Broadcast join is always used when we want to join a large PySpark DataFrame with a small DataFrame. The broadcast() function takes a small data frame as a parameter and broadcasts that data frame to all executors and each executor keeps that data frame in the memory for further Join operations.
Broadcast join is a vast topic in PySpark, You can below links to get a detailed tutorial about broadcast join.
Here, I am giving just ideas for using the broadcast() function.
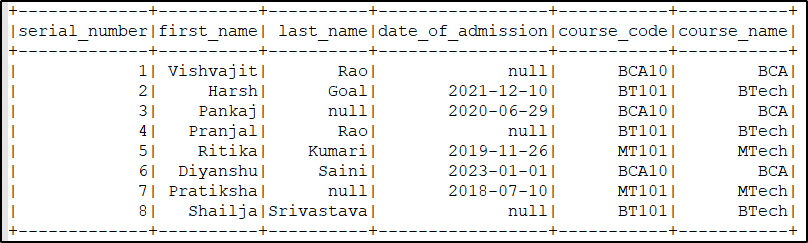
As we know, In the above created main PySpark DataFrame we have a column course_code which has contained course code and now we want to get the course name of each course code.
To get the course name I created a small PySpark DataFrame which contained only two values course code and their name after that I used the broadest join to broadcast that small DataFrame to all the executors in order to perform broadcast join as you can see below code.
The broadcast() function returns a DataFrame which is ready to perform broadcast join.
Example
from pyspark.sql import SparkSession
from pyspark.sql.functions import broadcast
# list of tuples
data = [
("1", "Vishvajit", "Rao", None, "BCA10"),
("2", "Harsh", "Goal", "2021-12-10", "BT101"),
("3", "Pankaj", None, "2020-06-29", "BCA10"),
("4", "Pranjal", "Rao", None, "BT101"),
("5", "Ritika", "Kumari", "2019-11-26", "MT101"),
("6", "Diyanshu", "Saini", "2023-01-01", "BCA10"),
("7", "Pratiksha", None, "2018-07-10", "MT101"),
("8", "Shailja", "Srivastava", None, "BT101"),
]
# column
column_names = [
"serial_number",
"first_name",
"last_name",
"date_of_admission",
"course_code",
]
# creating spark session
spark = SparkSession.builder.appName("www.programmingfunda.com").getOrCreate()
# creating large DataFrame
large_dataframe = spark.createDataFrame(data=data, schema=column_names)
# creating small PySpark DataFrame
small_dataframe = spark.createDataFrame(
data=[("BCA10", "BCA"), ("BT101", "BTech"), ("MT101", "MTech")],
schema=["code", "course_name"],
)
# creating broadcast variable
broadcast_variable = broadcast(small_dataframe)
# creating final dataframe
final_dataframe = large_dataframe.join(
broadcast_variable, large_dataframe.course_code == broadcast_variable.code
)
# displaying final DataFrame
final_dataframe.select(
"serial_number",
"first_name",
"last_name",
"date_of_admission",
"course_code",
"course_name",
).show()
After executing the above code the final Output will be like this.
coalesce(*col)
The coalesce() function returns the first column that is not null. It takes more than a column name or literal value as a parameter.
Let’s take an example to understand PySpark coalesce() function.
Example
In this example, I have replaced the None values in the date_of_admission column with the current date.
from pyspark.sql.functions import coalesce, current_date
# using coalesce() function
df = df.withColumn("date_of_admission", coalesce(df.date_of_admission, current_date()))
# displaying DataFrame
df.show()
Output
+-------------+----------+----------+-----------------+-----------+
|serial_number|first_name| last_name|date_of_admission|course_code|
+-------------+----------+----------+-----------------+-----------+
| 1| Vishvajit| Rao| 2023-05-13| BCA10|
| 2| Harsh| Goal| 2021-12-10| BT101|
| 3| Pankaj| null| 2020-06-29| BCA10|
| 4| Pranjal| Rao| 2023-05-13| BT101|
| 5| Ritika| Kumari| 2019-11-26| MT101|
| 6| Diyanshu| Saini| 2023-01-01| BCA10|
| 7| Pratiksha| null| 2018-07-10| MT101|
| 8| Shailja|Srivastava| 2023-05-13| BT101|
+-------------+----------+----------+-----------------+-----------+isnan(col)
The function isnan() is used to return True if the passed column name contained a nan value otherwise it returns False.
I have replaced some values in first_name with nan value.
Example
from pyspark.sql.functions import isnan
# using isnan() function
df = df.select(isnan(df.first_name).alias('isnan'))
# displaying DataFrame
df.show()
isnull(col)
The function isnull() is used to return True if the passed column is Null otherwise it returns False.
Example
from pyspark.sql.functions import isnull
# using isnull() function
df = df.select(isnull(df.last_name).alias('isnull'))
# displaying DataFrame
df.show()
Output
+------+
|isnull|
+------+
| false|
| false|
| true|
| false|
| false|
| false|
| true|
| false|
+------+rand(seed)
This function is used to generate a random column with independent and identically distributed. it takes the seed value as a parameter for the random generator.
Example
# using rand() function
df = df.withColumn('rand', rand())
# displaying DataFrame
df.show(4)
Output
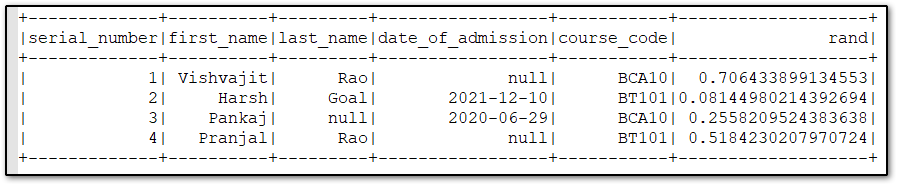
Note:- 4 in show() indicates the number of rows we want to get from PySpark DataFrame.
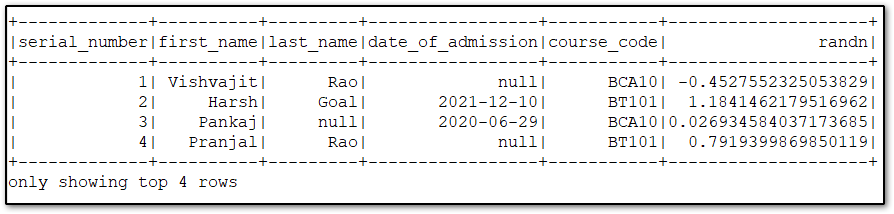
randn(seed)
This function same as the rand() function. The randn() generates the random values with standard normal distribution.
Example
from pyspark.sql.functions import randn
# using randn() function
df = df.withColumn('randn', randn())
# displaying DataFrame
df.show(4)
Output
when(condition, value)
The when(condition, value) function is one of the useful functions in PySpark DataFrame, If the condition evaluates True it returns the value of the value parameter. Remember, The return type of the when() function, is always PySpark Column instance. If the condition evaluates False the value passed in otherwise() function will return.
For example, I want to add a column course_name which will contain the course name based on the course code. The ‘BCA10‘ means ‘BCA‘, ‘BT101‘ means ‘BTech‘, and ‘MT101‘ means ‘MTech‘.
Example
# using when() function
df = df.select(
"first_name",
"last_name",
"course_code",
when(col("course_code").startswith("BCA"), "BCA")
.when(col("course_code").startswith("BT"), "BTech")
.when(col("course_code").startswith("MT"), "MTech")
.alias("course_name"),
)
# displaying DataFrame
df.show()
Output
+----------+----------+-----------+-----------+
|first_name| last_name|course_code|course_name|
+----------+----------+-----------+-----------+
| Vishvajit| Rao| BCA10| BCA|
| Harsh| Goal| BT101| BTech|
| Pankaj| null| BCA10| BCA|
| Pranjal| Rao| BT101| BTech|
| Ritika| Kumari| MT101| MTech|
| Diyanshu| Saini| BCA10| BCA|
| Pratiksha| null| MT101| MTech|
| Shailja|Srivastava| BT101| BTech|
+----------+----------+-----------+-----------+greatest(*col)
The greatest() function is used to return the greatest value from a list of passed column names. skipping null values. This function takes at least two arguments. It returns Null if all the parameter is Null.
Example
from pyspark.sql.functions import greatest
# using greatest() function
df = df.select(greatest('serial_number', 'first_name').alias('greatest'))
# displaying DataFrame
df.show(4)
Output
+---------+
| greatest|
+---------+
|Vishvajit|
| Harsh|
| Pankaj|
| Pranjal|
+---------+
only showing top 4 rowsleast(*col)
The least() function is used to return the least value from a passed list of column names. It skips the null value. It takes at least two parameters and it returns a null value if all the passed column names are null.
Example
from pyspark.sql.functions least
# using least() function
df = df.select(least('serial_number', 'first_name').alias('least'))
# displaying DataFrame
df.show(4)
Output
+-----+
|least|
+-----+
| 1|
| 2|
| 3|
| 4|
+-----+
only showing top 4 rowsPySpark Useful Tutorials
- Convert PySpark DataFrame Column to List
- How to Write PySpark DataFrame to CSV
- How to Convert PySpark DataFrame to JSON
- How to Apply groupBy in Pyspark DataFrame
- Merge Two DataFrames in PySpark with the Same Column Names
- Merge Two DataFrame in PySpark with Different Column Names
- How to drop duplicate rows from PySpark DataFrame?
- How to Count Null and NaN Values in Each Column in PySpark DataFrame?
- PySpark SQL DateTime Functions with Examples
- How to convert PySpark Row To Dictionary
- PySpark Column Class with Examples
- PySpark Sort Function with Examples
- How to read CSV files using PySpark
- PySpark col() Function with Examples
- Fill None or Null Values in PySpark DataFrame
- How to change the Data Type of a Column in PySpark DataFrame?
- How to drop one or multiple columns from PySpark DataFrame?
- PySpark SQL String Functions with Examples
👉 PySpark Normal Functions Documentation:- Click Here
Summary
So, In this article, we have seen almost all the PySpark normal built-in functions along with examples. These PySpark built-in functions play the most important role in real-life PySpark applications.
I hope the way of explanation of this article was easy and straightforward. You can use any PySpark normal built-in function according to your requirement for example, you can use the when() function to apply any condition on PySpark DataFrame, the col() function to return the Column instance, coalesce() function to return first not null values, etc.
If you found this article helpful, Please share and keep visiting for further PySpark tutorials.
Have a nice day……





