
In this article, we will see How to explode multiple columns in PySpark DataFrame with the help of the examples.PySpark provides a built-in function called explode() that is used to transform arrays into columns in PySpark DataFrame.
To use the explode() function first we need to import it from the pyspark.sql.functions module of the PySpark library because the explode() function is defined inside the pyspark.sql.functions module.
Headings of Contents
PySpark explode() Function
explode() is a built-in function in PySpark that is defined inside the pyspark.sql.functions module of the PySpark library. This function takes a column as a parameter and the column should be array-like so that it can create a new row for each item of the array.
Parameters:
Pandas explode() method accepts one argument:
- col:- Colume to be explode.
Explode Multiple Columns in PySpark DataFrame
To apply the PySpark explode() function we must have a PySpark DataFrame, let’s create a sample PySpark DataFrame along with some array-like columns.
Use this PySpark code to create a sample PySpark DataFrame.
from pyspark.sql import SparkSession
# list of tuples
data = [
("1", "Vishvajit", "Rao", ['Python', 'Java'], ['BCA', 'MCA']),
("2", "Harsh", "Goal", ['Excel', 'Accounting'], ['BCOM', 'MCOM']),
("3", "Pankaj", "Kumar", ['Video editing'], ['BCA', 'MCA']),
("4", "Pranjal", "Rao", ['HTML', 'CSS', 'JavaScript'], ['BCA', 'MCA']),
("5", "Ritika", "Kumari", ['Python', 'Java', 'R'], ['BCA', 'MCA']),
("6", "Diyanshu", "Saini", ['Python', 'HTML', 'CSS'], ['BCA', 'MCA']),
]
# columns
column_names = [
"serial_number",
"first_name",
"last_name",
"skills",
"course"
]
# creating spark session
spark = (
SparkSession.builder.master("local[*]")
.appName("www.programmingfunda.com")
.getOrCreate()
)
# creating DataFrame
df = spark.createDataFrame(data=data, schema=column_names)
df.show(truncate=True)
After executing the above code, The sample DataFrame will look like this.
+-------------+----------+---------+-----------------------+------------+
|serial_number|first_name|last_name|skills |course |
+-------------+----------+---------+-----------------------+------------+
|1 |Vishvajit |Rao |[Python, Java] |[BCA, MCA] |
|2 |Harsh |Goal |[Excel, Accounting] |[BCOM, MCOM]|
|3 |Pankaj |Kumar |[Video editing] |[BCA, MCA] |
|4 |Pranjal |Rao |[HTML, CSS, JavaScript]|[BCA, MCA] |
|5 |Ritika |Kumari |[Python, Java, R] |[BCA, MCA] |
|6 |Diyanshu |Saini |[Python, HTML, CSS] |[BCA, MCA] |
+-------------+----------+---------+-----------------------+------------+Now the requirement is to transform each item of the list or array in column skills and course into separate rows. Import explode() function from pysparl.sql.functions module.
Let’s see how can we do that.
Example: PySpark explode multiple columns
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
# list of tuples
data = [
("1", "Vishvajit", "Rao", ["Python", "Java"], ["BCA", "MCA"]),
("2", "Harsh", "Goal", ["Excel", "Accounting"], ["BCOM", "MCOM"]),
("3", "Pankaj", "Kumar", ["Video editing"], ["BCA", "MCA"]),
("4", "Pranjal", "Rao", ["HTML", "CSS", "JavaScript"], ["BCA", "MCA"]),
("5", "Ritika", "Kumari", ["Python", "Java", "R"], ["BCA", "MCA"]),
("6", "Diyanshu", "Saini", ["Python", "HTML", "CSS"], ["BCA", "MCA"]),
]
# columns
column_names = ["serial_number", "first_name", "last_name", "skills", "course"]
# creating spark session
spark = (
SparkSession.builder.master("local[*]")
.appName("www.programmingfunda.com")
.getOrCreate()
)
# creating DataFrame
df = spark.createDataFrame(data=data, schema=column_names)
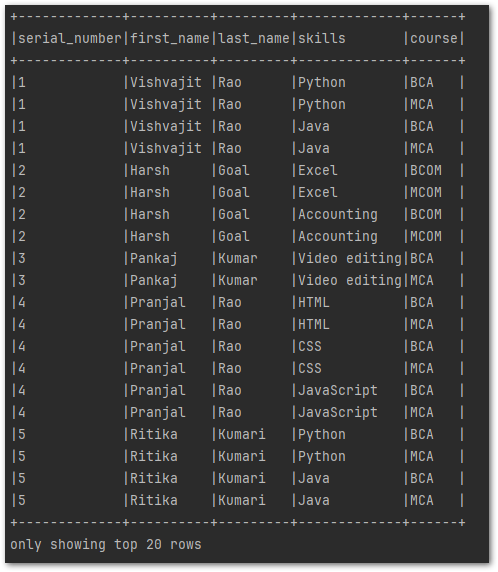
new_df = df.withColumn("skills", explode("skills")).withColumn("course", explode("course"))
new_df.show(truncate=False)
Output
Code Explanation:
Let’s see and understand the above code step by step.
- from imported the SparkSession to create the spark session from pyspark.sql
- Imported the explode() function from pyspark.sql.functions module
- Created the list of tuples and each tuples indicate the information of a single person like serial_number, first_name, last_name, skills, and course.
- Created a list called column_names that is indicating the column names in PySpark DataFrame.
- Created the spark session by using the SparkSession class.
- Created a PySpark DataFrame by using the createDataFrame() method.
- Applied the explode() method on skills and course column of DataFrame df.
- After applying the withColumn() method and explode() function, a new PySpark DataFrame is returned that is stored in the new_df column.
- And finally display the newly created DataFrame.
In the above example we have seen PySpark explode multiple columns, now let’s see how we can explode a single column.
Here, I am going to explode the skills column of the DataFrame.All the source code will be same, only .withColumn(“course”, explode(“course”)) part will be removed from the above code, as you can see below.
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
# list of tuples
data = [
("1", "Vishvajit", "Rao", ["Python", "Java"], ["BCA", "MCA"]),
("2", "Harsh", "Goal", ["Excel", "Accounting"], ["BCOM", "MCOM"]),
("3", "Pankaj", "Kumar", ["Video editing"], ["BCA", "MCA"]),
("4", "Pranjal", "Rao", ["HTML", "CSS", "JavaScript"], ["BCA", "MCA"]),
("5", "Ritika", "Kumari", ["Python", "Java", "R"], ["BCA", "MCA"]),
("6", "Diyanshu", "Saini", ["Python", "HTML", "CSS"], ["BCA", "MCA"]),
]
# columns
column_names = ["serial_number", "first_name", "last_name", "skills", "course"]
# creating spark session
spark = (
SparkSession.builder.master("local[*]")
.appName("www.programmingfunda.com")
.getOrCreate()
)
# creating DataFrame
df = spark.createDataFrame(data=data, schema=column_names)
new_df = df.withColumn("skills", explode("skills"))
new_df.show(truncate=False)
Output
+-------------+----------+---------+-------------+------------+
|serial_number|first_name|last_name|skills |course |
+-------------+----------+---------+-------------+------------+
|1 |Vishvajit |Rao |Python |[BCA, MCA] |
|1 |Vishvajit |Rao |Java |[BCA, MCA] |
|2 |Harsh |Goal |Excel |[BCOM, MCOM]|
|2 |Harsh |Goal |Accounting |[BCOM, MCOM]|
|3 |Pankaj |Kumar |Video editing|[BCA, MCA] |
|4 |Pranjal |Rao |HTML |[BCA, MCA] |
|4 |Pranjal |Rao |CSS |[BCA, MCA] |
|4 |Pranjal |Rao |JavaScript |[BCA, MCA] |
|5 |Ritika |Kumari |Python |[BCA, MCA] |
|5 |Ritika |Kumari |Java |[BCA, MCA] |
|5 |Ritika |Kumari |R |[BCA, MCA] |
|6 |Diyanshu |Saini |Python |[BCA, MCA] |
|6 |Diyanshu |Saini |HTML |[BCA, MCA] |
|6 |Diyanshu |Saini |CSS |[BCA, MCA] |
+-------------+----------+---------+-------------+------------+So this is how we can explode a single or multiple column into PySpark DataFrame.
Helpful PySpark Tutorials
- PySpark Normal Built-in Functions
- PySpark SQL DateTime Functions with Examples
- PySpark SQL String Functions with Examples
- Merge Two DataFrames in PySpark with Different Column Names
- How to Fill Null Values in PySpark DataFrame
- How to Drop Duplicate Rows from PySpark DataFrame
- PySpark DataFrame Tutorial for Beginners
- PySpark Column Class with Examples
- PySpark Sort Function with Examples
- PySpark col() Function with Examples
- How to read CSV files using PySpark
- How to Count Null and NaN Values in Each Column in PySpark DataFrame?
- Merge Two DataFrames in PySpark with Same Column Names
- How to Apply groupBy in Pyspark DataFrame
- How to Change DataType of Column in PySpark DataFrame
- Drop One or Multiple columns from PySpark DataFrame
- How to Convert PySpark DataFrame to JSON ( 3 Ways )
- How to Write PySpark DataFrame to CSV
- How to Convert PySpark DataFrame Column to List
- How to convert PySpark DataFrame to RDD
- How to convert PySpark Row To Dictionary
👉PySpark explode() Docs:- Click Here
Conclusion
In this article, we have seen how to explode multiple columns in PySpark DataFrame with the help of examples. There is a high chance in technical coding interviews, this question might be asked by the interviewer if you are going for a data engineering, or data analyst interview.
explode() function is one of the best functions in PySpark especially when you are looking for expoding the array-like column.
If you found this article helpful, please share and keep visiting for further pandas tutorials.





